Certified Kubernetes (Part 2)

This blog post will provide an introduction to Kubernetes, what it is, and how you can use it, and build an understand the fundamentals.
These are my personal notes I made while I was studying CKA and CKAD certifications.
I passed the CKAD with 78/100 exam score, and I passed the CKA with 85/100 exam score. The minimum score to pass the certification is 66 over 100.
Overview
Here's what we'll discuss in this post. You can click on any top-level heading to jump directly to that section.
Table of Contents
- The Kubernetes Architecture
- Basic Notions
- Labels, Selectors and Annotations
- Config, Secrets and Resource Limits
- Pod Scheduling
- Probes for Containers
- Logging & Monitoring
- POD Design
- Services
- State Persistence & Storage
- Networking
- Security
- Users Permissions and Management
- Design and Install K8s Cluster & kubeadm
- Cluster Maintenance
- Troubleshooting
- Others
The Kubernetes Architecture
In this section there are some basic concepts and terms related to Kubernetes (K8s) architecture. The purpose is to provide the knowledge about the main components.
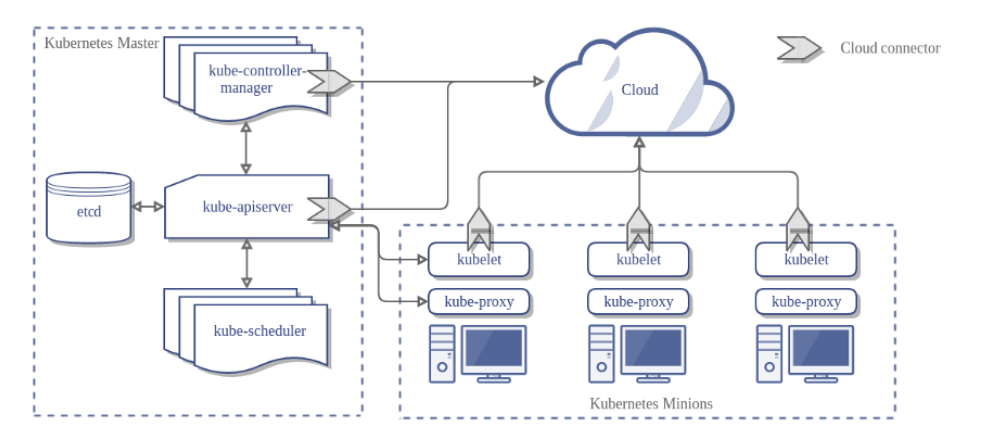
Cluster: A Kubernetes cluster consists of one or more nodes managed by Kubernetes. If our a node fails, your app will be down. So a cluster is a set of nodes grouped together. Even if one node fails, your application will still be accessible from the other nodes. In addition, having multiple nodes helps in sharing the computational load as well.
Master Node: It is s responsible for managing the cluster. For example it store the information about the members of the cluster, if a node node fails it is responsible to move the workload of the failed node to another worker node. In addition, it monitor the nodes into the cluster.
The master nodes runs the Kubernetes control plane. The control plane consists of different processes, such as an API server, scheduler, controller manager and etcd.
- Kube-APIServer: This component exposes the Kubernetes API, it is the front-end for the control plane. The users, management devices, and command line interfaces all talk to the API server to interact with the Kubernetes cluster.
- Kube-Scheduler: It is a component on the master node that watches newly created pods that have no node assigned and selects a node for them to run on.
- ETCD: is a distributed reliable key-value store used by Kubernetes to store all data used to manage the cluster. It stores the configuration information which can be used by each of the nodes in the cluster, and other information about resources like pods, deployments, etc. It is usually installed on the master, but it can also be deployed on multiple nodes. It stores the data of the database at /var/lib/etcd.
- Kube-Controller-manager: It has many logically separate functions, but to reduce complexity all runs in a single process. Those functions are the Node Controller that is responsible for noticing and responding when nodes go down, the Replication Controller that is responsible for maintaining the correct number of pods for every replication controller object in the system and the Endpoints Controller that is responsible to populate the Endpoints of Services and Pods.
- Cloud-Controller-Manager: When it comes to the cloud there is another component that interact with the underlying cloud providers. It has many other functions like the Service Controller that is responsible for creating, updating, and deleting cloud provider load balancers, the Volume Controller that is responsible of creating, attaching, and mounting volumes and Service Account and Token Controllers that is responsible for create default accounts and API access tokens for new namespaces.
Nodes (Minions): In a Kubernetes cluster each machine has a dedicated role, can be master or worker. The master is our API point, the workers are in charge of running the app. The machines that acts as workers, used to be called nodes or minions.
The worker nodes runs different processes, such as kubelet, kube-proxy and docker.
- Docker: helps in running the encapsulated application containers in a relatively isolated but lightweight operating environment.
- Container Runtime: is the software that is responsible for running containers. Kubernetes supports several runtimes: Docker, containerd, cri-o, rktlet, and any implementation of the Kubernetes CRI (Container Runtime Interface).
- Kubelet: is the agent that runs on each node in the cluster. Usually, it communicates with the master component to receive commands and work, interacts with the ETCD store to read configuration details and write values. The Kubelet process then assumes responsibility for making sure that the containers are running on the nodes as expected. It manages network rules, port forwarding, etc. Kubelet can also deploy Static PODs independently, the agent constantly monitors the /etc/kubernetes/manifest path and deploy everything inside. The Kubelet doesn’t manage containers that were not created by Kubernetes.
- Kubernetes Proxy Service: is a proxy service that runs on each node and helps to make the service available to external hosts. It helps to forward requests to the correct container and is able to perform raw load balancing.
Client: Kubernetes follows a client-server architecture where the client use a command line tool to interact with the cluster.
- Kubectl: command is a line tool that interacts with kube-apiserver and send commands to the master node. Each command is converted into an API call. If the API Interface fails also the line tool stops working, in this case you have to ssh into the cluster and use docker commands to troubleshoot the problem.
Kubernetes uses client certificates, bearer tokens, or an authenticating proxy to authenticate API requests, you can check the location and credentials that kubectl knows about with this command: kubectl config view. The default location of .kube/config file in linux is ~/.kube/config.

Basic Notions
PODs: From K8s docs, pods are the smallest deployable units of computing that you can create and manage in Kubernetes. If you need to run a single container in Kubernetes, then you need to create a Pod for that container.
- A Pod can contain more than one container, usually these containers are relatively tightly coupled. A container can be a Docker container, rkt container, or a virtual machine (VM).
- Containers in a Pod run on a “logical host”; they use the same network namespace, and use shared volumes. It makes possible for these containers to efficiently communicate. Ci sono tre principali pattern nel Multi-Container PODs e sono: Sidecar, Adapter e Ambassador.
- Scaling operation creates new PODs, it replicates all containers in the POD.
- You can attach a Label to a Pod. Labels can be used to organize and to select subsets of objects.
- Each Pod is assigned a unique IP address. Inside a Pod the containers that belong to the Pod can communicate with one another using localhost.
- PODs can communicate each other via IP address only if in the same node. To connect PODs in a Cluster, you need a network manager such as Calico.
apiVersion: v1 kind: Pod metadata: name: hello
spec: containers: - name: hello image: busybox command:
- '/bin/sh'
args:
- '-c'
- 'while true; do echo hello; sleep 10; done'
env:
- name: APP_COLOR
value: pink
- name: APP_BACKGROUND
valueFrom:
configMapKeyRef: ConfigMapName
- name: API_KEY
valueFrom:
secretKeyRef: SecretName
- You can specify the environment variables by using the env property. In the above example, the value is taken from different sources.
- When te container starts it execute the actions that are specified under the command and args sections. In the case of the example the container executes /bin/sh -c "while true; do echo hello; sleep 10; done".
- The command section in Kubernetes is the same as ENTRYPOINT in docker, while the args section in Kubernetes is the same as COMMAND in docker.
To create a POD you can use the below command:
$ kubectl run nginx --image=nginx --dry-run=client -o yaml > pod.yaml
By using a --dry-run=client option you can generate a sample YAML file, just customize it and create the POD with kubectl apply -f pod.yaml command.
ReplicaSets: From K8s docs, a ReplicaSet ensures that a specified number of pod replicas are running at any given time, deployment instead is a higher-level concept that manages ReplicaSets.
- It is an holder for PODs, for each POD in the holder it monitors the execution status, with a ReplicaSets you can control how many PODs are in the holder.
- In order to manage failures you have to provide PODs YAML definition.
- It does not give you a strategy to replace PODs in the holder, check Deployment for this.
Deployment: From K8s docs, a Deployment provides declarative updates for Pods and ReplicaSets along with a lot of other useful features. You have to use Deployments instead of ReplicaSets, unless you require custom update orchestration or don't require updates at all. This actually means that you may never need to manipulate ReplicaSet objects.
- When you create a Deployment also a ReplicaSets is automatically created.
- You can use strategy section in order to specify the release mode, it can be Rolling Update or Big Bang (Recreate in k8s).
- The RollingUpdate strategy has some additional settings with which you can specify how many PODs at most can be down at a time during the deployment.
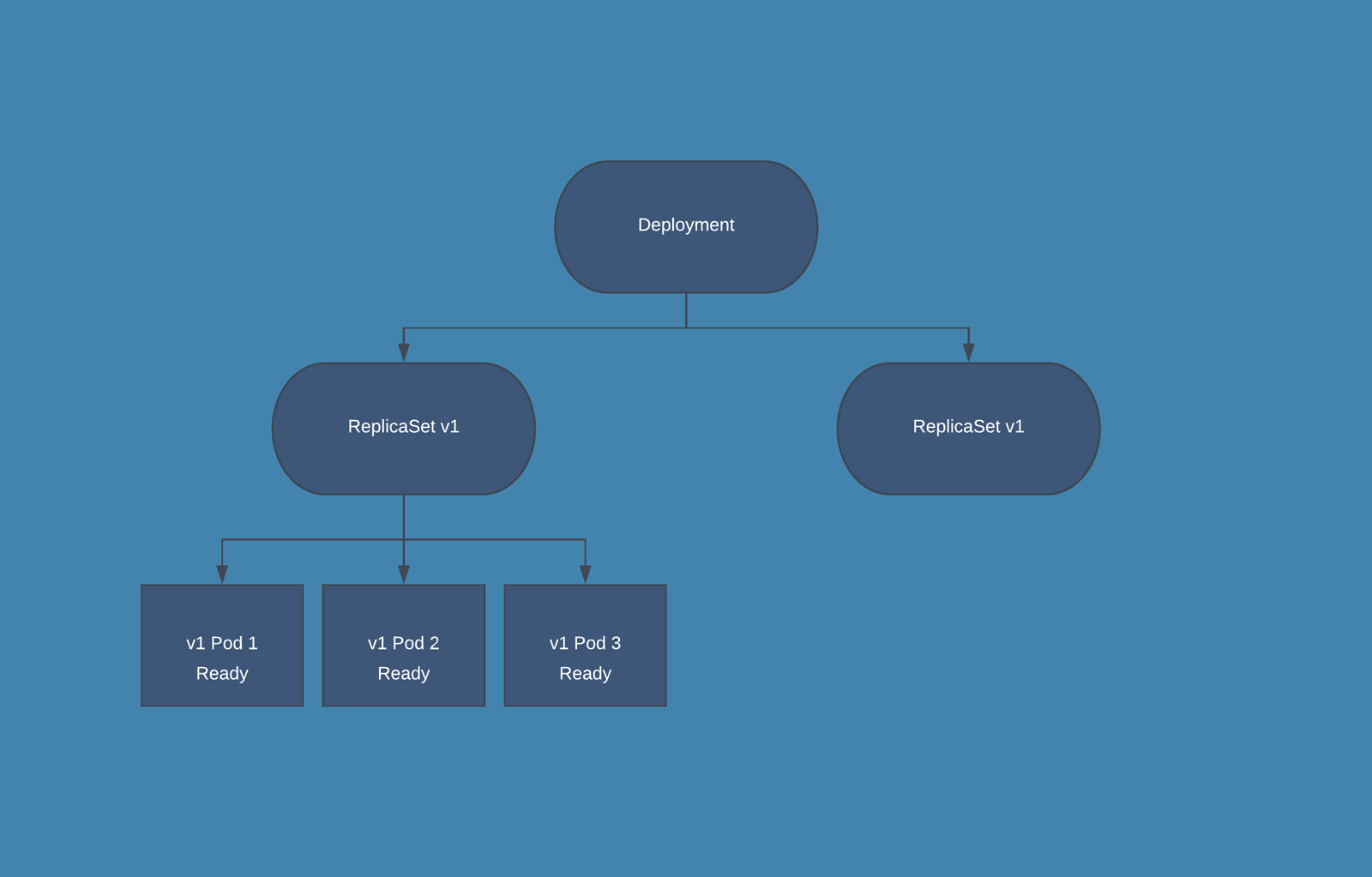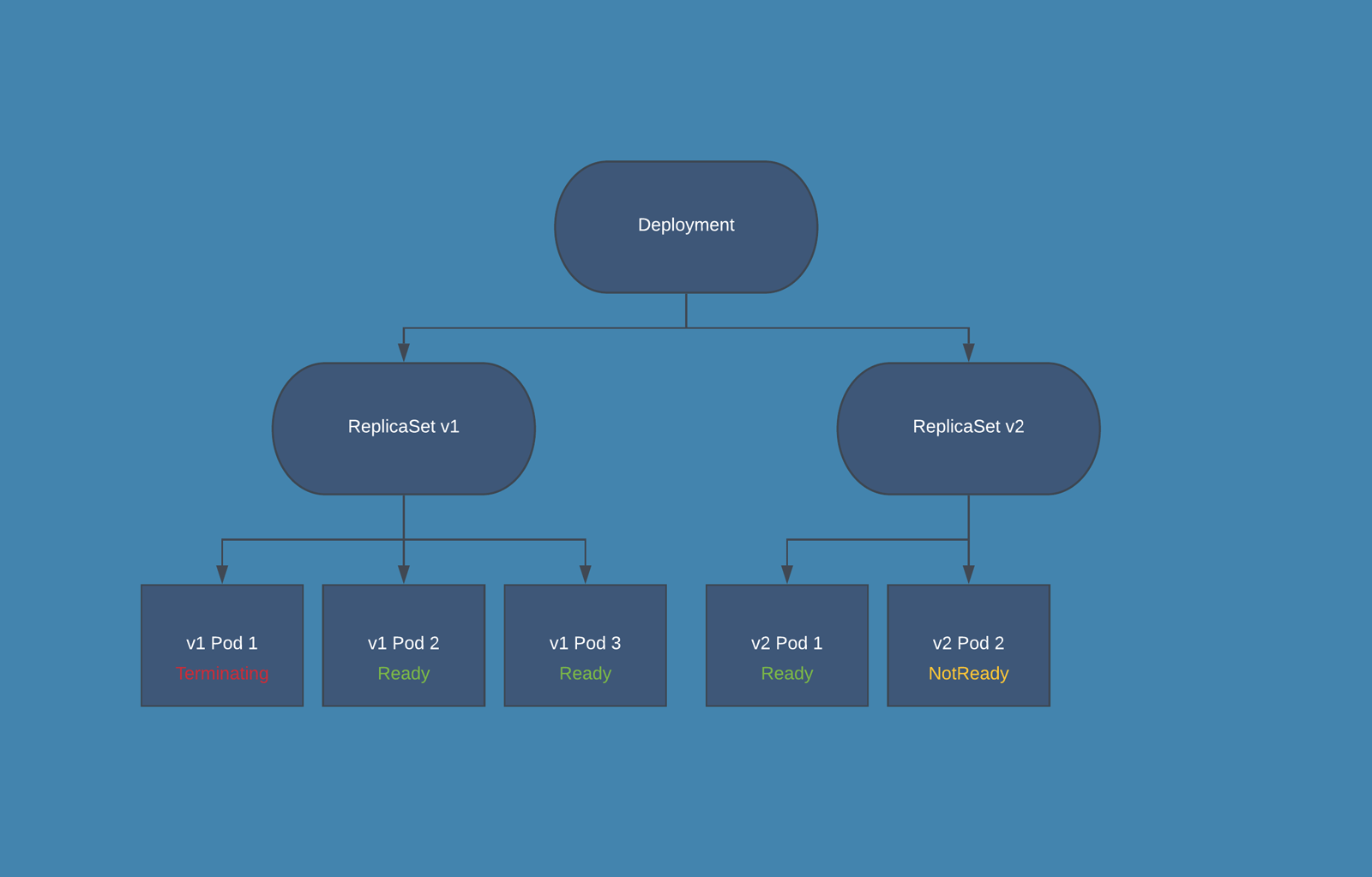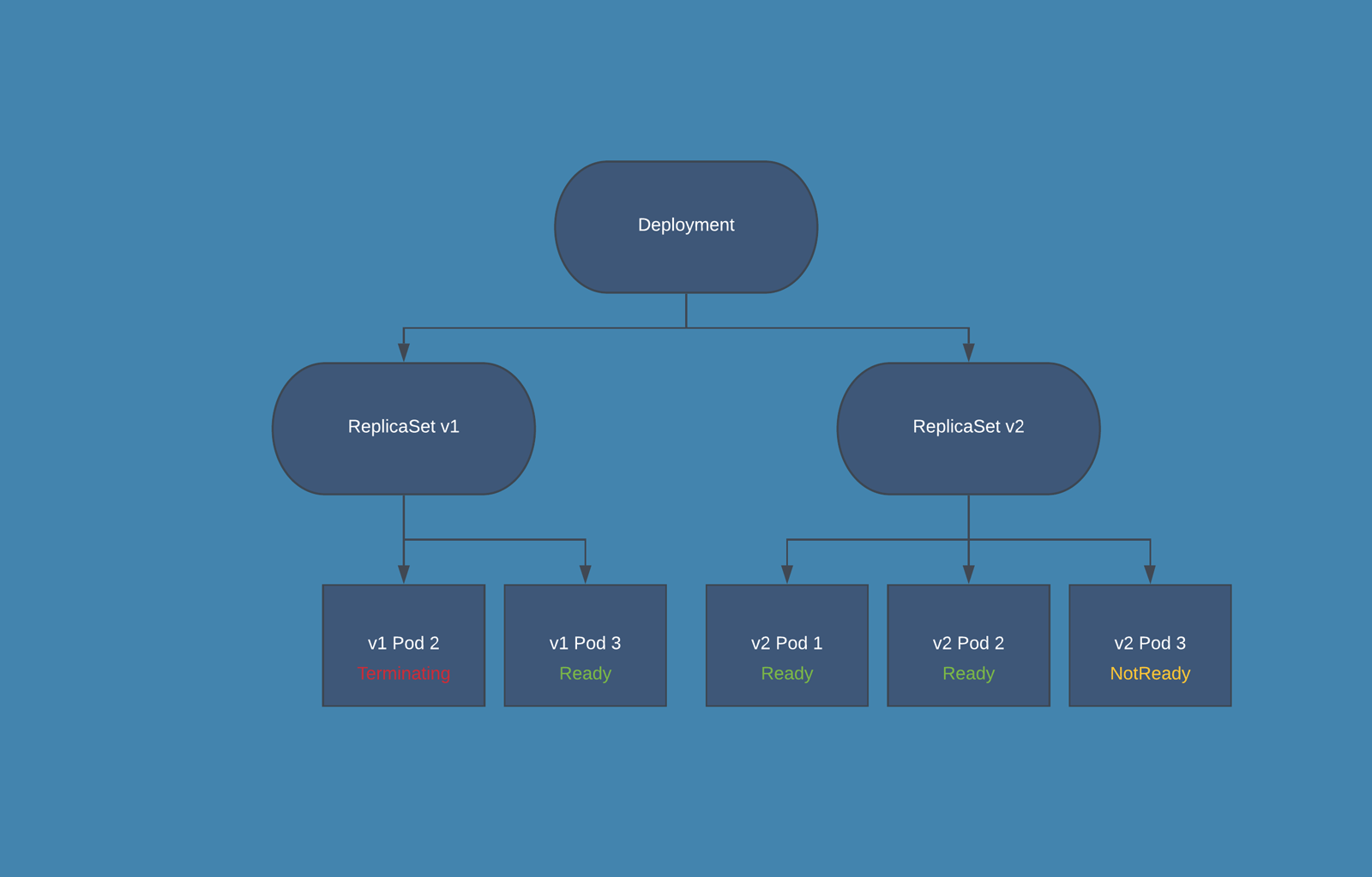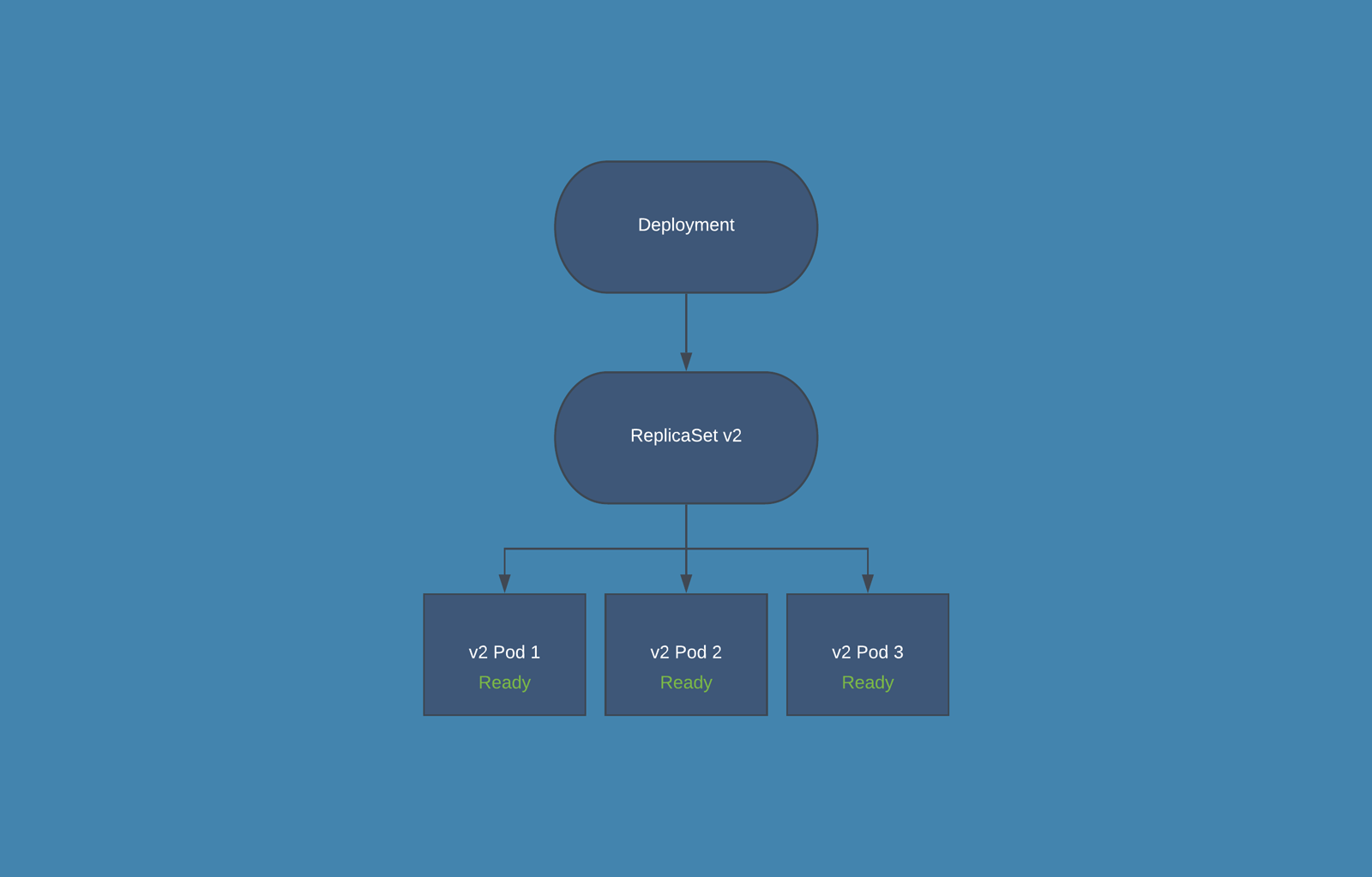
- During the release phase the Deployment creates a new ReplicaSet in which new PODs are created, according to the release settings the old PODs are deleted from the first ReplicaSet and new PODs are started in the second one.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
replicas: 3
selector:
matchLabels:
app: nginx
template:
# This is the pod template
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# The pod template ends here/pre>- In the above example to switch from RollingUpdate to Recreate you have to delete the rollingUpdate section, and set the property strategy.type:Recreate. In this case, Kubernetes deletes in a single step old PODs from the first ReplicaSet and creates new PODs in the second one.
- The YAML of the Deployment resource also contains the definition of the pod used by the underlying ReplicaSet to start new resources. To identify which resource belongs to a Deployment - and therefore to the underlying ReplicaSet - Kubernetes uses labels. The selector.matchLabels section selects all the POD with the label app=nginix.
- To be selected by a Deployment, the POD must specify the same label app=nginix into the metadata.labels section.
To create a Deployment you can use the below commands:
$ kubectl create deployment --image=nginx nginx --dry-run -o yaml > deployment.yaml
By using a --dry-run=client option you can generate a sample YAML file, just customize it and create the Deployment with kubectl apply -f deployment.yaml command. If you update the definition, the deployment creates new PODs by following the release strategy. You can perform rollback operation by using this command:
$ kubectl rollout undo deployment/myapp-deployment
Namespaces: From K8s docs, Namespaces are a way to divide cluster resources between multiple users, teams or projects. It provide a scope for names and resources in namespace need to be unique, but not across namespaces. You cannot create a nested namespace and each resource can only be in one of it.
- Some namespaces are created automatically by Kubernetes.
- Default, unless otherwise specified everything is created within this namespace.
- kube-system contains what is needed to run k8s, while kube-public here is where the resources that are to be made available to all users should be created.
- Resources in a Namespace can reach others using the name.
- For resources in a different Namespace you need to add the namespace name and svc.cluster.local. For example, db-service.dev.svc.cluster.local consists of <service-name>.<namespace>.svc.cluster.local where svc stands for Service and cluster.local is the ClusterDomain.
- ResourceQuota can be used to limit the resources that can be used for resources in a namespace.
To create a Namespace you can use the below commands:
$ kubectl create namespace test --dry-run=client -o yaml
# namespace.yaml
apiVersion: apps/v1 kind: Namespace metadata: name: test creationTimestamp: null spec: {}
status: {}
$ kubectl apply -f namespace.yaml
DaemonSets: From K8s docs, a DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
- DaemonSets are used to ensure that some or all of your K8S nodes run a copy of a pod, which allows you to run a daemon on every node.
- When you add a new node to the cluster, a pod gets added to match the nodes.
- When you remove a node from your cluster, the pod is put into the trash.
- Deleting a DaemonSet cleans up the pods that it previously created.
- DaemonSets are useful for deploying different types of agents.
- The typical use case for a DaemonSet is logging and monitoring for the hosts.
Jobs: From K8s docs, Jobs are a way to ensure that one or more pods execute their commands and exit successfully. When all the pods have exited without errors, the Job gets completed. When the Job gets deleted, any created pods get deleted as well.
- There are many scenarios when you don’t want the process to keep running indefinitely.
- You can use jobs to perform batch operations.
- The Default behavior for PODs does not make them useful to implement this, because k8s would recreate them each time to ensure that the required number of PODs are running. You can get around this by properly configuring restartPolicy:Never however it would still be a workaround.
- You can use Jobs to handle the case where you need to parallelize data transformation. In this case, the Job makes ensures that each task has correctly completed the operation.
To create a Job you can use the below commands:
$ kubectl create job job-test --image=busybox --dry-run=client -o yaml
# job.yaml
apiVersion: batch/v1 kind: Job metadata: name: job-test creationTimestamp: null spec:
spec:
parallelism: 2
completions: 6
template:
# This is the pod template
metadata:
name: job-terst
creationTimestamp: null
spec:
containers:
- image: busybox
name: batch
resources: {}
command: ["echo","job-test"]
restartPolicy: OnFailure
# The pod template ends here
status: {}
By using a --dry-run=client option you can generate a sample YAML file, just customize it and create the Job with kubectl apply -f job.yaml command. The above example executes six jobs with a parallelism of two.
Cron Jobs: From K8s docs, Cron Jobs are useful for periodic and recurring tasks, like running backups, sending emails, or scheduling individual tasks for a specific time, such as when your cluster is likely to be idle.
- You can use CronJobs for cluster tasks that need to be executed on a predefined schedule.
- For example log rotation command should not be running continuously. It gets scheduled, and once the task is executed, it returns the appropriate exit status that reports whether the result is a success or failure.
StatefulSets:
Init Container: From K8s docs, an init container is the one that starts and executes before other containers in the same Pod. It’s meant to perform initialization logic for the main application hosted on the Pod.
- An Init Container is defined in the same way as a container for a Pod, but in the initContainers section.
- Init containers are started and executed at POD startup and before the main containers, so it is a good candidate for delaying the application initialization until one or more dependencies are available.
- You can have multiple Init containers in same POD, they are started and executed in sequence. An init container is not invoked unless its predecessor is completed successfully.
- You can use Init containers to create the necessary user accounts, perform database migrations, create database schemas and so on.
- If any of the init containers fail, the whole Pod is restarted, unless you set restartPolicy to Never.
- Restarting the Pod means re-executing all the containers again including any init containers. You may need to ensure that the startup logic tolerates being executed multiple times.
- All containers on the same Pod share the same Volumes and network. You can make use of this feature to share data between the application and its init containers. You can use Init Container to download a configuration and make it available to other containers.
apiVersion: v1 kind: Pod metadata: name: database spec:
initContainers:
- name: fetch
image: busybox/wget
command:
- '/bin/sh'
args:
- '-c'
- 'wget site.url/dmp.sql -o /docker-entrypoint-initdb.c/dump.sql'
volumeMounts:
- mountPath: /docker-entrypoint-initdb.c
name: dump
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "admin"
volumeMounts:
- mountPath: /docker-entrypoint-initdb.c
name: dump
volumes:
- emptyDir: {}
name: dump
In the example above the InitContainer is used to download the dump.sql file which is then shared via the volume to the mysql container.
Static Pod: From K8s docs, static Pod are managed directly by the kubelet daemon on a specific node, without the API server observing them. The kubelet watches each static Pod and restarts it if it fails.
- a static Pod is defined at the /etc/kubernetes/manifest path on each node.
- are mainly used by k8s administrators to create system components.
- a change to a Static Pod using the edit command has no effect. Since kubelet monitors what is created in the static pods folder it is necessary to update the pod definition in the specific folder.
- a change to a static pod using the edit command has no effect.
- kubelet retrieves the definition of static pods from the /etc/kubernetes/manifest path, so you must edit the pod definition in that path for the change to take effect.
Example, create the static pod static-busybox that uses the busybox image and executes the "sleep 1000" command.
$ kubectl run --restart=Never --image=busybox static-busybox --dry-run=client -o yaml --command -- sleep 1000 > /etc/kubernetes/manifests/static-busybox.yaml
apiVersion: v1 kind: Pod metadata:
labels:
run: static-busybox name: static-busybox spec:
initContainers:
- name: static-busybox
image: busybox
command:
- sleep
- '1000'
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}

Labels, Selectors and Annotations
Labels & Selectors:
>>> kubectl get pods --selector app=App1
>>> kubectl get all --selector env=prod,bu=finance,tier=frontend
- La relazione tra Deployment e POD è definita tramite Labels
- La relazione tra ReplicaSet e POD è definita tramite Labels
- La relazione tra Service e PODs è definita tramite Labels
- Le annotazioni servono a dare informazioni aggiuntive, ad esempio la versione del applicazione.
https://blog.getambassador.io/kubernetes-labels-vs-annotations-95fc47196b6d
Annotations

Config, Secrets and Resource Limits
Earlier you saw how PodSpecs can be used to define the container images that should be instantiated in the pods. Follow the best practice of portability: Make sure that your pods can run consistently without needing to change your container images for development or production. This can be done by separating your configuration data from your application code.
Config Map: To separate your configuration data from your application code in Kubernetes you can use a ConfigMap. A ConfigMap is an API object that stores data as key-value pairs. Other Kubernetes objects, such as pods, can then use the key values from the ConfigMap. The ConfigMap data can be used as environment variables, command line arguments, or as configuration files in a volume.
- to use a ConfigMap there are two steps, first you have to create the config map in key/value form and then you have to do injection of it into the Pod.
- you can use the whole content of the ConfigMap as Env, or you can import a single key and set is as environment variable, also you can mount the ConfigMap as Volume.
- when you mount the ConfigMap as a volume many files are created at mount path. The application can retrive the value from the file named using key.
Example, how to crear a ConfigMap
$ kubectl create configmap config-map-example --from-literal=foo=bar --from-literal=wow=baz --dry-run=client -o yaml
apiVersion: v1 kind: ConfigMap data:
foo: bar wow: baz metadata:
creationTimestamp: null
name: config-map-example
Example, how to inject a ConfigMap into a Pod
apiVersion: v1 kind: Pod metadata: name: hello
spec: containers: - name: hello image: busybox
# Option 1
# Import the whole key/value map as Env
envFrom:
- configMapRef:
name: ConfigMapName
key: foo
# Option 2
# Import the single value as Env
env:
- name: APP_BACKGROUND
valueFrom:
configMapKeyRef: ConfigMapName
# Option 3
# Crete foo and wow files in the mount path
# The foo file contains "bar" string
# The wow file contains "baz" string
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: ConfigMapName
Secrets: A ConfigMap is meant to store only nonconfidential data. All confidential data, such as AWS credentials, should be stored in Secrets. Secrets protect and encrypt confidential and sensitive information. Do not store confidential information directly in your pod definition or in your ConfigMap because that information is not secure and can be compromised.
Secrets store sensitive information in key-value pairs such as passwords.
- Note that the values for all keys in the data field of a secret must be base64-encoded strings.
- quando monti un secret come volume vengono creati dei file che contengono i dati, uno per ogni chiave.
- to make secrets really safe you must follow security best practices, by default secrets are only base64 encoded.
- with the declarative mode the secret value must be base64 encoded first:
echo "mysql" | base64
echo "bXlzcWwK" | base64 --decode - with the imperative mode the encoding is performed automatically.
Example, how to crear a Secret:
$ kubectl create secret generic db-secret --from-literal=DB_Host=sql01 --from-literal=DB_User=root --from-literal=DB_Password=password123 --dry-run=client -o yaml
apiVersion: v1 kind: Secret data:
DB_HOST: c3FsMDE= DB_Password: cGFzc3dvcmQxMjM=
DB_User: cm9vdA== metadata:
creationTimestamp: null
name: db-secret
Example, how to inject a Secret into a Pod
apiVersion: v1 kind: Pod metadata: name: hello
spec: containers: - name: hello image: busybox
# Option 1
# Import the whole key/value map as Env
envFrom:
- secretRef:
name: SecretName
# Option 2
# Import the single value as Env
env:
- name: DB_Password
valueFrom:
secretKeyRef:
name: SecretName
key: DB_Password
# Option 3
# Crete DB_HOST, DB_Password and DB_User files in the mount path
# The DB_HOST file contains "sql01" string
# The DB_Password file contains "password123" string
# The DB_User file contains "root" string
volumeMounts:
- name: secret-volume
mountPath: /etc/secret
volumes:
- name: secret-volume
secret:
secretName: SecretName
Resource Requirements, Resource Limits
Requests and limits are the mechanisms Kubernetes uses to control resources such as CPU and memory. Requests and limits are on a per-container basis, each container in the Pod gets its own individual limit and request, but because it’s common to see Pods with multiple containers you need to add the limits and requests for each container together to get an aggregate value for the Pod.
To control what requests and limits a container can have, you can set quotas at the Container level and at the Namespace level. There are two types of resources: CPU and Memory.
A typical Pod spec for resources might look something like this. This pod has two containers:
apiVersion: v1 kind: Pod metadata: name: resource-limits
spec: containers: - name: hello1 image: busybox
resources:
requests:
memory: '32Mi'
cpu: '200m'
limits:
memory: '64Mi'
cpu: '250m'
- name: hello2 image: busybox
resources:
requests:
memory: '96Mi'
cpu: '300m'
limits:
memory: '192Mi'
cpu: '750m'
Each container in the Pod can set its own requests and limits, and these are all additive. So in the above example, the Pod has a total request of 500 mCPU and 128 MiB of memory, and a total limit of 1 CPU and 256MiB of memory.
- CPU resources are defined in millicores.
- Memory resources are defined in bytes.
- Default: 500m CPU and 256 Mi RAM.
If the node where a Pod is running has enough of a resource available, it's possible (and allowed) for a container to use more resource than its request for that resource specifies. However, a container is not allowed to use more than its resource limit.
ResourceQuotas
A resource quota provides constraints that limit aggregate resource consumption per namespace. A Quota for resources might look something like this:
apiVersion: v1 kind: ResourceQuota metadata: name: quota
spec: hard: request.cpu: '500m' request.memory: '100Mib'
limits.cpu: '700m'
limits.cpu: '500Mib'
- requests.cpu As long as the total requested CPU in the Namespace is less than 500m, you can have 50 containers with 10m requests, five containers with 100m requests, or even one container with a 500m request.
- requests.memory As long as the total requested Memory in the Namespace is less than 100MiB, you can have 50 containers with 2MiB requests, five containers with 20MiB CPU requests, or even a single container with a 100MiB request.
- limits.cpu and limits.memory is the maximum combined CPU or Memory.
You can also create a LimitRange in your Namespace. Unlike a Quota, which looks at the Namespace as a whole, a LimitRange applies to an individual container. This can help prevent people from creating super tiny or super large containers inside the Namespace.

Pod Scheduling
This is one of the key components of Kubernetes master responsible for distributing the workload or containers across multiple nodes. The scheduler is responsible for workload utilization and allocating pod to a new node. It looks for newly created containers and assigns them to Nodes. Factors taken into account for scheduling decisions include individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines.
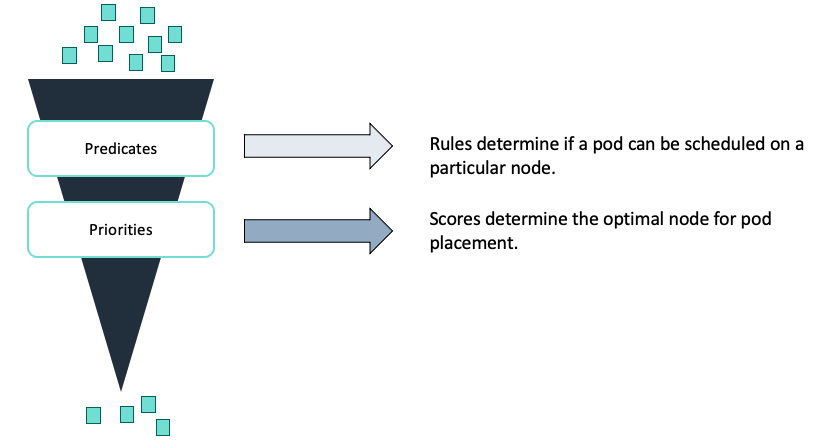
The scheduler uses filters to exclude ineligible nodes for pod placement and then determines the final node based on a scoring system. Predicates determine which nodes are ineligible. This can be due to volume, resource, or topology requirements. Priorities calculates a score for each node that has not been filtered out. Then, the scheduler places the pod on the highest-scoring node. If there are no available nodes remaining after all filters have been applied, scheduling fails.
Predicate: Volume requirements
The volume filter checks the pod’s volume requirements to determine which nodes are compatible. For storage backends that are topology-constrained and not globally accessible from all Nodes in the cluster you must know the Pod's requirements, otherwise this may result in unschedulable Pods. For example, an Amazon EBS volume in one Availability Zone cannot be attached to a node in a different Availability Zone. Similarly, a pod might require a specific volume that is already mounted on a node. In this case, you must place that pod on the same node.
Predicate: Resource requirements
The scheduler considers which nodes have the resources required by the pod. This includes things such as CPU, memory, disk space, and available ports. As you already know, resource requirements are defined at the container level, so the sum of resources requested for all containers defines the resources for the pod. The scheduler uses the number of resources when making a scheduling decision. Nodes cannot be overprovisioned, so if your cluster does not have enough resources for the pod, scheduling fails.
The limits parameter defines a finite limit on resources after the pod is running. A running container can burst resource usage from the original request up to the defined limit. If the container uses more resources than the limit allows, the scheduler terminates the container.
Predicate: Topology – Taints and tolerations
After satisfying volume and resource constraints, the scheduler considers constraints that have been set to fine-tune pod placement. You can set up scheduling constraints at the node level and at the pod level.
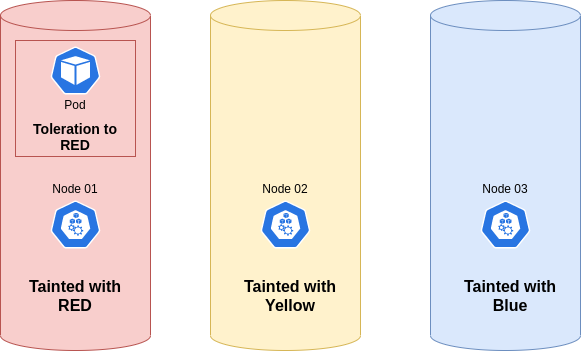
Taints and tolerations are settings that work together to control which pods can be placed on a particular node.
Taints are a property of nodes that prevent the placement of pods. A tainted node accepts only pods that specifically tolerate the taint. To taint a node, specify a key=value pair, such as skynet=false, and then add an action that defines when the taint is considered.
You can configure the scheduler to respect the taint during scheduling, in this case no pod will be scheduled on this node unless the pod has a matching toleration.
A toleration is a property of a pod that specifies that it can run on a tainted node. A toleration must match a specific taint.
You can apply a toleration to a specific pod that matches the taint that was set up earlier. The scheduler is now allowed to place this pod onto the tainted node, but it may also schedule it somewhere else based on other constraints.
- tolerations are used to specify which Pod can be scheduled on a certain node
- If a node has a taint=blue then only the Pod with tolerations=blue can be scheduled on the node
- you can specify the effect of a taint: NoSchedule, the Pod will not be scheduled on the node; PreferNoSchedule, the system tries not to schedule the Pod on the node but it is not guaranteed; NoExecute: new Pod will not be scheduled on the node, existing PODs on the node are terminated and moved elsewhere.
- to add a toleration to a Pod it is necessary to specify the property tolerations.
- it does not define a preference for a particular node, to deploy a Pod on a specific node you have to use Node Affinity.
Predicate: Topology – Node Selectors
- serve a specificare su quale nodo deve essere deployato un POD in base ad una label
- kubectl label nodes <node-name> <label-key>=<label-value>
- usato per criteri di selezione molto semplici.
- va specificata la proprietà "nodeSelector"
How PODs are scheduled?
Manual Scheduling, Taint and Tolerations, Node Selectors, Node Affinity
- Se non presente va specificato a mano il nodo su cui fare il deploy. Viene usata l'opzione "nodeName"
- Se si usa lo scheduler di default l'opzione "nodeName" non va specificata.
Predicate: Topology – Affinity
At times, you may need to make sure that a pod is scheduled on a specific node. Suppose the pod requires a specific hardware resource, such as a graphics processing unit (GPU) or solid state drive (SSD). To make sure that a pod runs on a specific node or instance type, you can use affinity settings. When combined with taints and tolerations, affinity settings make sure that only pods with a correct toleration can be scheduled to a node.
With a nodeAffinity setting, you can make sure that your pod only runs on some instance types. There are two types of node affinity:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
You can think of them as “hard” and “soft,” respectively. The hard specifies rules that must be met for a pod to be scheduled onto a node. The soft specifies preferences that the scheduler will try to enforce but will not guarantee. The “IgnoredDuringExecution” part of the names means that if labels on a node change at runtime such that the affinity rules on a pod are no longer met, the pod continues to run on the node.
The "preferredDuringScheduling" means that the scheduler will try to run this set of pods on a specific node, however, if that’s not possible, the set is allowed to run elsewhere.
You can also specify affinity and anti-affinity at the pod level to control how pods should be placed relative to other pods. For example, with anti-affinity scheduling, you can make sure that your pods don’t end up on the same node. Do this to make sure the scheduler doesn’t create a single point of failure for a certain pod.
- Node Affinity and Node Selectors are almost the same, but Node Affinity allows you to specify more complex selection criteria.
- you can use "NotIn" to exclude some values or "Exists" to check if a specific key exists.
Aggiungere una foto descrittiva
Node Affinity vs Taints & Tolerations
- Node Affinity allows you to schedule a pod=red on a node=red but does not avoid pod=grey on node=red. For a Node it allows a Pod with a specific color-label but does not preclude other colors from landing on the same node.
- Taints & Tolerations prevents pod=green from going on node=red, but does not preclude pod=green from going on node=blanck. It moves PODs of a certain color away from a differently colored node, but there is no control over where among the non-colored nodes the Pod is deployed.
Aggiungere una foto descrittiva
Predicate: Topology – DaemonSet
A DaemonSet ensures that all nodes have a copy of the requested pod. This is useful when you want to provide common supporting functionality (such as security, logging, monitoring, or backups) for the pods running your application code. For example, if you need to collect logs from nodes, you can run a DaemonSet. Doing this ensures that a logging daemon pod, such as Fluentd, is run on all nodes. If you delete a DeamonSet, you also delete any pods it created across all the nodes.
You can run these daemons in other ways, such as with an init script instead of a DaemonSet. However, you can use DaemonSets to do the following:
- Monitor and manage logs for daemons like any other application.
- Maintain an ecosystem of similar Kubernetes toolsets and API clients.
- Isolate daemons from application containers.
Replace pods deleted because of unavoidable circumstances, such as node failure.
https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/
Custom Scheduler
Scheduler:
- puoi creare il tuo scheduler, deployarlo e renderlo di default.
- ci possono anche essere più schedulers.
>>> usare l'opzione --leader-elect=true in caso di HA per eleggere uno scheduler tra quelli disponibili e deployati sui vari master. Se invece l'obiettivo è usare più scheduler questa opzione va messa a false. L'opzione --lock-object-name=my-custom-scheduler serve a differenziare lo scheduler custom dal default durante il processo di elezione.
>>> usare l'opzione --scheduler-name=my-custom-scheduler per definire il nome dello scheduler per differenziarlo da quello di default.
- puoi usare "schedulerName" nello spec del container per selezionare lo scheduler da usare in caso siano più di uno
- il comando "kubectl get events" può essere usato per vedere gli eventi e quindi gli interventi del nuovo scheduler.
- Se stai deployato più scheduler solo quello che aggiungi deve avere l’opzione --leader-elect=false! Non modificare quello esistente.
- Devi trovare una porta libera per lo scheduler: netstat -tunap | grep <porta>
- La porta trovata va aggiunta come porta di container e bisogna modificare gli altri check: livenessProbe etc.
- nodeSelector necessita dello scheduler
- nodeName, per selezionare dove deployare il POD, funziona senza scheduler
Multiple Schedulers

Probes for Containers
Distributed systems can be difficult to manage because they involve many moving parts, all of which must work for the system to function. Even if small part breaks, it needs to be detected, routed and fixed, and these actions need to be automated. Kubernetes allows us to do this with the help of probes, but before that we need to understand what is the lifecycle of a Pod.
These are the different phases:
- When the pod is first created, it starts with a pending phase. The scheduler tries to figure out where to put the pod. If the scheduler cannot find a node to place the pod on, it will remain pending.
- Once the pod is scheduled, it goes to the container creating phase, where the images needed by the application are pulled and the container starts.
- Next, it moves to the running phase, where it continues until the program is completed successfully or terminated.
Kubernetes gives you the following types of health checks:
- Readiness probes: This probe will tell you when your application is ready to serve traffic. Kubernetes makes sure the readiness probe passes before allowing the service to send traffic to the pod. If the readiness probe fails, Kubernetes will not send traffic to the pod until it passes. Kubernetes waits the probe before setting the container to the Ready state, this is very useful in the multi-container case, each could have different start times. What would happen if the application inside container on one of the PODs freezes? New users are impacted, the Pod is Ready even if it is not Alive.
readinessProbe:
httpGet: ( tcpSocket | exec )
path: /api/ready
port: 8080
initialDelaySeconds: 10 # Aspetta 10 secondi
periodSeconds: 5 # Ricontrolla ogni 5 sec
failureThreshold: 8 # Dopo 8 tentativi Fail
- Liveness probes: Liveness probes will let Kubernetes know if your application is healthy. If your application is healthy, Kubernetes will not interfere with the functioning of the pod, but if it is unhealthy, Kubernetes will destroy the pod and start a new pod to replace it. In the kube-controller-manager you can set the option --pod-eviction-timeout which defines how long to wait before replacing a Pod after a failure. The Pod is replaced only if it is part of a ReplicaSet or Deployment. What would happen if the application inside container on one of the Pods freezes? The probe allows to specify a condition to check if the application is still ready to receive traffic from users, so if you freeze the application the Pod would be restarted automatically.
livenessProbe:
httpGet:
path: /api/healthy
port: 8080
<opzioni-come-prima>
- Startup probes: Startup probes will let Kubernetes know when the container application starts. If such a probe is configured, it disables Liveness and Readiness checks until it succeeds. This can be used with slow-starting containers, preventing them from being killed before they are up and running.
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10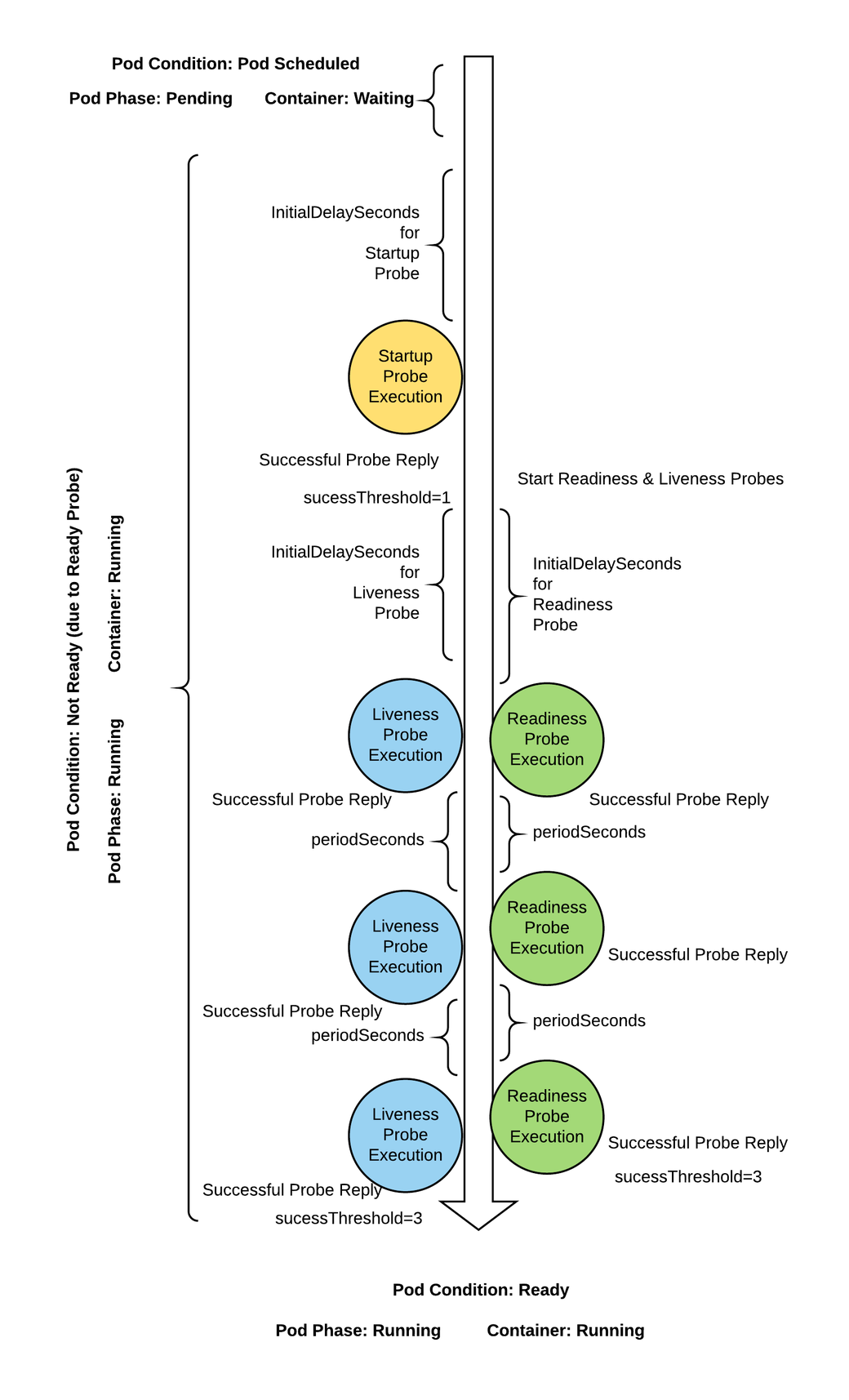

Logging & Monitoring
Node Selectors Logging, Monitor Cluster Components, Application Logs, (Logging & Monitoring CKAD)
Monitor:
- Node level Metrics: Numbers of Nodes, Numbers of Healthy Nodes, Performance Metric = CPU, Memory, Network, Disk
- Pod Level Metrics: Number of PODs, Performance Metric = CPU, Memory
- Esistono diverse soluzioni per raccogliere le metriche: Metric server, Prometheus, Elastic Stack, Datadog, dynatrace.
- kubectl top node / kubectl top pod
Log:
- per visualizzare i log bisogna dare il comando:
>>> kubectl logs -f event-simulator-pod
- l’opzione -f serve a rimanere in ascolto sul POD e visualizzare i log appena vengono generati.
- se ci sono più container in un pod va specificato il nome del container nel comando.
- per visualizzare i log senza kubectl bisogna dare il comando
>>> docker logs container-id

POD Design
Architectural patterns are ways to solve common problems. In a distributed solution, there is a set of common functions independent of business logic: logging, configuration, security, etc. Due to the need to implement these functions outside the business container and reuse them as necessary, patterns called sidecars, ambassadors or adapters are used.
- Sidecar: As with motorcycles, the sidecar is placed next to the bike itself, the sidecar container is also positioned next to the legacy container, to extend its functionality. For example, you have a web service capable of responding to HTTP requests from clients and you want to evolve the solution by adding a security layer, thus implementing the HTTPS protocol. In this case you can use a sidecar container to implement the security layer and is independent of the business logic, can be reused where needed and encapsulate SSL certificates Management. You can use the same approach to extend service API or to collect logs from legacy container and push to monitor service, without having to change the code of the original container. This pattern is similar to the Decorator in object oriented programming.
Aggiungere immagine descrittiva del Sidecar
- Ambassador: This pattern comes in handy when access to a service needs to be redirected according to a new policy. One of the most interesting applications of ambassador containers is for the Canary Deploy, let's imagine that you want to test a new version of a microservice, you can use an ambassador container to spins a desired percentage of traffic to the new container. This pattern is similar to the Proxy in object oriented programming.
Aggiungere immagine descrittiva del Ambassador
- Adapter: In this pattern, an adapter container offers standardized output and interfaces across multiple heterogeneous main application containers. In other words, you need to adopt an exposed interface of our legacy container so that it becomes usable by an external service on which we have no opportunity to intervene. In contrast to the ambassador pattern, which presents an application with a simplified view of the outside world, adapters present the outside world with a simplified, homogenized view of an application. An example of using adapter containers is the introduction of a legacy container monitoring layer, to collect metrics data and provide it to applications such as CloudWatch. This pattern is similar to the Adapter in object oriented programming.
Aggiungere immagine descrittiva del Adapter

Services
Service is an abstraction level that Kubernetes uses to make a deployed application accessible from the internal and external of the cluster. While Pods are the basic entities, a Service acts as a layer above the pods and enable the communication between different pods in a cluster.

Consider the above example. Our application has groups of pods running, some pods are running in a Deployment, other two pods are running as single pod. Some pods have app:A label, while an other has the app:B label. The service selects all the pods with the app:A label. The service does not care if the pods are running in a Deployment or not.
You can create a web application, where you have pods serving front-end, other to serve back-end processes and finally a group for database. Each group has its own label, you can use services to enable connectivity between these group of pods and to decouple components. Also, services helps front-end apps to be made available to end users.
Types of services in Kubernetes
Kubernetes supports five different types of services:
- Cluster IP
- NodePort
- Load Balancer
- ExternalName
- Headless Services
Services can be exposed in different ways by specifying a type in the ServiceSpec.
ClusterIP service is the default Kubernetes service. Exposes the Service on an internal IP in the cluster. This type makes the Service only reachable from within the cluster. Therefore we use this type of service when we want to expose a service to other pods within the same cluster. Each node runs a kube-proxy container, which creates iptable rules on each host to redirect ClusterIP to the appropriate pods IPs. This type of service is useful for frontend pods to reach backend pods or to act as load balancers.
The YAML for a ClusterIP service looks like this:
apiVersion: v1
kind: Service
metadata:
name: backend-clusterIP
spec:
type: ClusterIP
selector:
app: backend
ports:
- name: http
port: 80 # port of this service exposes within the cluster
targetPort: 80 # port on the pod(s) to forward traffic to
protocol: TCP
NodePort service is similar to a ClusterIP service except that it also opens a port on each node. It is the most easiest way to get the external traffic directly to your service. Opening the ports allows access to the service from inside the cluster (using the ClusterIP), while external parties can connect directly to the node on the NodePort. So, any traffic that comes to this port is forwarded to the service.
When a request is made from the internet, the request is sent to a single instance on a specific port. For each service, a randomly chosen port is opened on the local node, kube-proxy updates the iptables rules that forward traffic from the node port to the service's cluster IP and then to the pods.
The service in the below example listens on port 32001 and load balances the request to one of the WebApp pods, which then handles the request.
apiVersion: v1
kind: Service
metadata:
name: FrontendService
spec:
selector:
app: webapp
type: NodePort
ports:
- name: http
port: 80 # port of this service exposes within the cluster
targetPort: 80 # port on the pod(s) to forward traffic to
nodePort: 32001 # port on the node where external traffic will come in on
protocol: TCP
LoadBalancer service type extends the NodePort service by adding an external load balancer in the current cloud (if supported) and assigns a fixed, external IP to the Service. It is a superset of NodePort that creates a load balancer in front of all nodes.
The load balancer does not detect where the pods for a given service are running. Consequently, all worker nodes are added as backend instances in the load balancer. When a request is made from the internet, the request first arrives at the load balancer, then it forwards the request to one of the instances on a specific port. The load balancer routes the request to the nodes through an exposed port.
The FrontEnd service in this example is listening on RANDOM port and load balances this to one of the BackEnd pods, which handles the request. The external Load Balancer is listening on port 80.
apiVersion: v1
kind: Service
metadata:
name: FrontendService
spec:
selector:
app: webapp
type: LoadBalancer
ports:
- name: http
port: 80 # port where external traffic will come in on
targetPort: 9376 # port on which the service send requests to Pod
# nodePort <Random: The service generates it>
ExternalName service type allow connection to a resource outside the cluster. Maps the Service to the contents of the externalName field (e.g. foo.bar.example.com), by returning a CNAME record with its value. For example, you can create a service called Database and point it to an external database endpoint. Pods that require access to the database connect to the database service, which returns the Amazon RDS endpoint.
This type of service is helpful if you decide to migrate the external resource to the Kubernetes cluster. Deploy the database in the cluster and update the service type to ClusterIP. The application can continue to use the same endpoint.
apiVersion: v1
kind: Service
metadata:
name: Database
spec:
type: ExternalName
externalName: my.db.example.com
Headless Service is a service you can use when don't need load-balancing and a single Service IP. Usually, each connection to the service is forwarded to one randomly selected backing pod. If you perform a DNS lookup for a service, the DNS server returns a single IP, the service’s cluster IP.
Headless service instead allow the client to connect to all backing pods. If you tell Kubernetes you don’t need a cluster IP for your service, the DNS server will return the pod IPs instead of the single service IP. Instead of a single DNS A record, the DNS server will return multiple A records for the service, each pointing to the IP of an individual pod backing the service at that moment.
You can create what are termed "headless" Services, by explicitly specifying "None" for the cluster IP (.spec.clusterIP).
A typical use case for headless service is to interface with other service discovery mechanisms, without being tied to Kubernetes' implementation. The new service discovery mechanisms can therefore do a simple DNS A record lookup and get the IPs of all the pods that are part of the service, and then use that information to connect to one, many, or all of them.
The YAML for a Headless Service looks like this:
apiVersion: v1
kind: Service
metadata:
name: backend-clusterIP
spec:
clusterIP: None
selector:
app: backend
ports:
- name: http
port: 80 # port of this service exposes within the cluster
targetPort: 80 # port on the pod(s) to forward traffic to
protocol: TCP
How to access to Services
Quando crei un servizio questo è accessibile nello stesso namespace usando il suo nome, ad esempio: curl http://service-name . Nel namespace di default il nome di dominio completo è il seguente service-name.default.scv.cluster.local . In alternativa, se il servizio viene creato in un namespace specifico allora per accedere ad esso da un namespace differente è necessario specificare anche il nome del namespace in cui il servizio è stato creato, ad esempio: curl http://service-name.namespace-name . Come prima il nome di dominio completo è il seguente service-name.namespace-name.scv.cluster.local . In definitiva, lo stesso servizio può essere indirizzato usando:
- service-name
- service-name.namespace-name.scv
- service-name.namespace-name.scv.cluster.local
dove cluster.local è il root domain del cluster. Non può essere spezzato.
By default kubernetes non assegna un dominio ai Pod, questa feature va fatta abilitata manualmente aggiornato la configurazione di coreDNS, essa è salvata in /etc/coredns/Corefile, nella doc (https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/) è possibile trovare la configurazione di CoreDNS.
Nel file di configurazione possiamo notare la definizione di
- cluster.local: il root domain del cluster
- pods insecure: per associare un name al pod 10-244-1-5.dafault… la conversione del IP nel formato con i trattini è disattivata di default.
Solitamente il Corefile è passato al POD come oggetto configmap. La componente CoreDNS si occupa di aggiungere al suo database le informazioni necessarie ogni volta che un Pod o Servizio viene creato. Anche la componente CoreDNS espone un servizio kubernetes, necessario affinché i Pod possano raggiungere la componente.
La configurazione del DNS è fatta automaticamente dal kubelet che aggiunge l’informazione sul nameserver nel file /etc/resolv.conf all'interno del Pod. Sempre nel file /etc/resolv.conf c'è anche la regola search per indirizzare i servizi senza usare il nome completo.
Further considerations about Services
Unlike Pod, which is scheduled on a specific node, when a service is created it becomes visible to all other Pods within the cluster. Services are objects that exist at the cluster level, in fact they don't exist at all, they are virtual objects: there is actually no server listening on IP:PORT of the service. A service is just a kube-proxy configuration. kube-proxy creates rules in several ways: userspace, ipvs, iptables: (Default). You can go deeper on this by using kubernetes doc. You can view the translation setting using the command iptables -L -t net | grep <...>. (Verificare questo comando)
The kube-proxy logs are in /var/log/kube-proxy.log on each node.
I Service per funzionare hanno bisogno del network plugin. Infatti, senza il network plugin il service non può indirizzare tutti i Pod.
All'interno del cluster il range di IP assegnato ai Pod deve essere diverso da quello assegnato ai Service, non si devono mai sovrapporre. Si può ottenere il range di riferimento utilizzando i comandi di seguito.
Per i service abbiamo:
$ kubectl get pod kube-apiserver-kind-control-plane -n kube-system -o yaml
spec:
containers:
- command:
- kube-apiserver
- [..]
- --service-cluster-ip-range=10.96.0.0/16
- [..]
Per i Pod abbiamo:
$ kubectl get pod kube-controller-manager-kind-control-plane -n kube-system -o yaml
spec:
containers:
- command:
- kube-controller-manager
- [..]
- --cluster-cidr=10.244.0.0/16
- [..]
In caso di sovrapposizione il Pod non viene deployato poiché non è possibile assegnare un IP, si può però eseguire il Pod in None Network.
What network range are the nodes in the cluster part of? Run the command ip addr and look at the IP address assigned to the ens3 interfaces. Get network range from that. (Verificare ens3).

State Persistence & Storage
The biggest problem with managing persistent state is deciding where it should reside. There are three options available when deciding on where your persistent storage should live, and each has its own merits:
- Your persistent storage lives inside of the container. This can be useful if the data is replicable and non-critical, but you will lose data whenever a container restarts.
- Your persistent storage lives on the host node. This bypasses the ephemeral container problem, but you run into a similar problem since your host node is vulnerable to failure.
- Your persistent storage lives in a remote storage option. This removes the unreliability of storage on the container and host, but requires some careful thought and consideration into how you provision and manage remote storage.
Applications do require different level of persistence, as there are obviously varying levels of criticality for different applications. So before start you need to ask yourself how to design a stateful application, if your application require data to persist across both container and host restarts, you can use remote storage options.
Kubernetes provides a way for Pods to interact with remote (or local) storage options.

Here you can find:
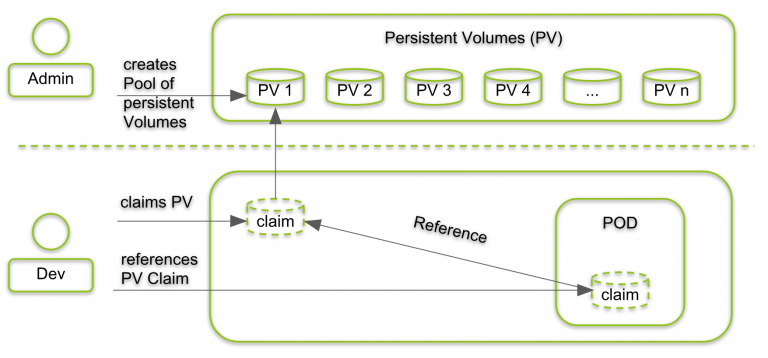
- Volumes can be viewed as a directory that containers in a pod can access. The mounted storage that persists for the lifetime of the enclosing Pod.
- PersistentVolume (PV) is storage in your cluster that has already been provisioned and is independent of any individual pod.
- PersistentVolumeClaim (PVC) is a request for storage by a user.
- StorageClasses are used to describe different storage options.
In static approach, a cluster administrator creates a number of PVs. They carry the details of the real storage, which is available for use by cluster users. In dynamic approach, when none of the static PVs the administrator created match a user's PersistentVolumeClaim, the cluster may try to dynamically provision a volume specially for the PVC.
Pods can have access to shared volumes by (1) creating a PersistentVolumeClaim with a specific amount of storage requested and with certain access modes, (2) a control loop finds a match (if possible) with a PersistentVolume, (3) and binds them together. Finally, the Pod can mount the PVC as Volume.
If cluster administrators want to offer varied PVs without exposing volume implementation details, they can use StorageClasses.
Kubernetes support many storage types, the CSI is a standard for exposing arbitrary block and file storage systems to containerized workloads. AWS provides CSI drivers for the different types of storage you can expose to Kubernetes. Using CSI, third-party storage AWS can write and deploy plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code.
Kubernetes Volumes
When you start a docker container, the engine creates an additional layer to save changes. This layer will be deleted when the container terminates. Volumes will outlive any containers that spin up/down within that Pod, giving us a nice workaround to the ephemeral nature of containers.
Volumes can be used to persist changes, you can mount an existing folder or an empty one. This PodSpec example includes a Volume named redis-persistent-storage, which is mounted on the container.
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
containers:
- name: ubuntu
image: ubuntu:18.04
command: ["echo"]
args: ["Hello World"]
volumeMounts:
- name: redis-persistent-storage
mountPath: /data/redis
volumes:
- name: redis-persistent-storage
emptyDir: {}
[...]
As we can see from the Pod definition above, the .spec.volumes section specifies the name of the Volume and the ID of the type (an EmptyDir Volume in this case). To use this Volume, the container definition must specify the Volume to mount in the .spec.container.volumeMounts field.
Kubernetes provides many types of Volumes and a Pod can use any number of them simultaneously, here you can fin a volume types list. Here is how to use a volume in Kubernetes to save Pod data in a specific path on the host:
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /opt
name: data-volume
volumes:
- name: data-volume
hostPath:
path: /data
type: Directory
While Volumes solve a huge problem for containerized applications, certain applications require the lifetime of the attached Volume to exceed the lifetime of a Pod. For this use case, Persistent Volumes and Persistent Volume Claims will be useful.
Kubernetes Persistent Volumes
You can save data in the node directory, but if Pod is restarted on another node, the data will still be lost. Persistent Volumes (PVs) are persistent storage available in the cluster and provided by the administrator. These PVs exist as cluster resources, just like nodes, and their lifecycle is independent of each individual Pod. A request for a persistent volume (PVC) is a user's request for storage (PV). Just as Pods consume node resources (e.g., memory and CPU), PVCs consume PV resources (e.g., storage).
The lifecycle of PVs is comprised of four stages: provisioning, binding, using, and reclaiming. The Persistent Volume definition specifies the capacity of the storage resource, as well as some other attributes, such as reclaim policies and access modes.
Below you will find a Persistent Volume definition.
apiVersion: v1
kind: PersistentVolume
metadata:
name: persistent-volume
spec:
capacity:
storage: 8Gi
accessModes:
— ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
awsElasticBlockStore:
volumeID: <volume-id> # This AWS EBS Volume must already exist.
Kubernetes Persistent Volume Claims
The user can consume PVs created by the administrator through PVCs. The Persistent Volume Claim definition defines the attributes that the persistent volume has to approve; some of these are storage capacity, access modes, storage class, etc. There is a one-to-one biding between PVCs and PVs. Labels and Selectors can be also used to specify a particular type of PV to query.
Kubernetes tries to optimize space, but if it cannot, it bind the PV to a larger PVC.
Below you will find a Persistent Volume Claims definition.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: persistent-volume-claim
spec:
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8Gi
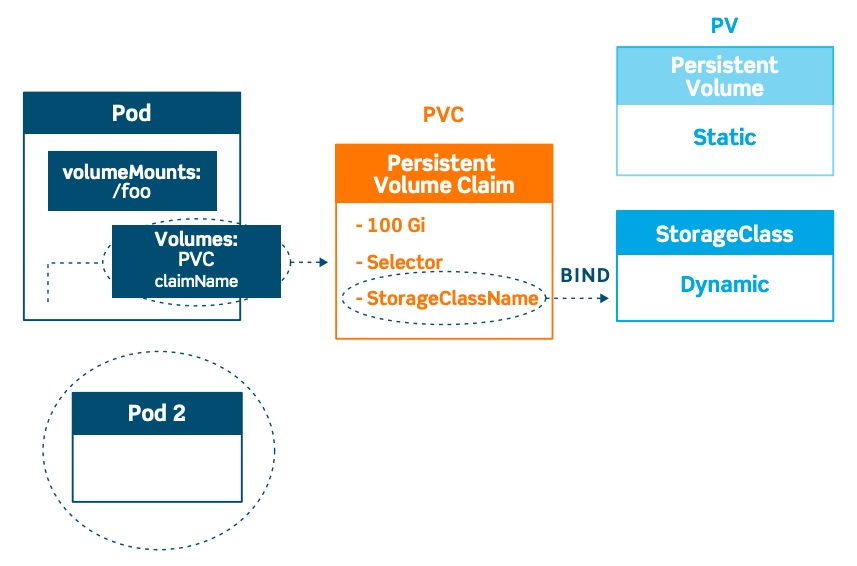
Kubernetes Storage Classes
You can use Persistent Volume Claim to reference a manually created Persistent Volume or use StorageClass. Kubernetes storage classes provide a way to dynamically provision storage resources at the time of the request. Compared to the previous case where the Pod connected to the PVC by specifying a name, the PVC now connects to the StorageClass by specifying a StorageClassName.
Storage Classes allow for cluster administrators to describe the “classes” of storage that they offer and leverage these “classes” as a template when dynamically creating storage resources.
Below you will find a Storage Class definition.
apiVersion: v1
kind: StorageClass
metadata:
name: storage-class
provisioner: kubernetes.io/aws-ebs
reclaimPolicy: Retain
parameters:
type: io1
iopsPerGB: 10
fsType: ext4
Here you can see there are three main objects:
- Reclaim policies: only Retain or Delete are available..
- Provisioners: is in charge of deciding which volume plugin needs to be used when provisioning PVs.
- Parameters: are related with a particular provisioners and these parameters are used to describe the specifications for the particular “class” of storage.
Kubernetes Storage
Having now the definition of persistent volumes, persistent volume claims and storage classes, let try to put it all together. Volumes will outlive any containers that spin up/down within that Pod, giving us a nice workaround to the ephemeral nature of containers. Persistent Volumes and Persistent Volume Claims provide a way to abstract the details of how storage is provisioned from how it is consumed.
The lifecycle of PVs is comprised of four stages:
- Provisioning: can be done in two ways: statically or dynamically. Static configuration requires the cluster administrator to manually create the number of PVs to be consumed. Dynamic provisioning can occur when the PVC requests a PV without any manual intervention by the cluster administrator, and requires storage classes.
- Binding: When it’s created, a PVC has a specific amount of storage and certain access modes associated with it. When a matching PV is available, it will be exclusively bound to the requesting PVC for however long that PVC requires. If a matching PV does not exist, the PVC will remain unbound indefinitely. In the case of dynamically provisioned PVs, the control loop will always bind the PV to the requesting PVC. Otherwise, the PVC will get at least what they asked for in terms of storage, but the volume may be in excess of what was requested.
- using
- reclaiming.
Using — Once the PVC has claimed the PV, it will be available for use in the enclosing Pod as a mounted Volume. Users can specify a specific mode for the attached Volume (e.g. ReadWriteOnce, ReadOnlymany, etc.) as well as other mounted storage options. The mounted PV will be available to the user for as long as they need it.
Reclaiming — Once a user is done utilizing the storage, they need to decide what to do with the PV that is being released. There are three options when deciding on a reclamations policy: retain, delete, and recycle.
- Retaining a PV will simply release the PV without modifying or deleting any of the contained data, and allow the same PVC to manually reclaim this PV at a later time.
- Deleting a PV will completely remove the PV as well as deleting the underlying storage resource.
- Recycling a PV will scrub the data from the storage resource and make the PV available for any other PVC to claim.
You can delete the PVC, this will not delete the PV. The default behavior of the PV is retain; it cannot be used by other PVCs.
- persistentVolumeReclaimPolicy: Retain
- persistentVolumeReclaimPolicy: Delete
- persistentVolumeReclaimPolicy: Recycle
PersistentVolumes, the default reclaim policy is Delete. This means that a dynamically provisioned volume is automatically deleted when a user deletes the corresponding PersistentVolumeClaim. If Recycle, the data in the PV are erased, so the Volume can be used by other PVCs.
You can use the previous Storage Class within a Persistent Volume Claim
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage-class-pvc
spec:
storageClassName: storage-class
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8Gi
An example Pod definition that leverages Persistent Volume Claims for requesting storage can be seen below:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
— name: test-container
image: nginx
volumeMounts:
— mountPath: /data
name: pvc-volume
volumes:
— name: pvc-volume
persistentVolumeClaim:
claimName: persistent-volume-claim
When comparing this Pod definition with the earlier one utilizing Volumes, we can see that they are nearly identical. Instead of directly interacting with the storage resource, the Persistent Volume Claim is used to abstract away storage details from the Pod.
If we compare the PVC definition to the one above used in the statically provisioned use case, we’ll see that they are identical.
This is due to the clear separation between storage provisioning and storage consumption. When comparing the consumption of Persistent Volumes when created with a Storage class versus when created statically, we see some huge advantages. One of the biggest advantages is the ability to manipulate storage resource values that are only available at resource creation time. This means that we can provision exactly the amount of storage that the user requests without any manual intervention from the cluster administrator. Since Storage Classes need to be defined ahead of time by cluster administrators, they still maintain control over which types of storage are available to their end-users while also abstracting away all provisioning logic.
https://medium.com/capital-one-tech/conquering-statefulness-on-kubernetes-26336d5f4f17

Networking
Ci sono tre reti, bridge, none, host.
DNS, CNI, Cluster Networking, Pod Networking, Network Policies, Ingress
Networking - Intro:
- https://www.tecmint.com/ip-command-examples/
- Ipotizziamo che uno switch crea una rete in 192.168.1.0, il seguente comando assegna / toglie l'interfaccia specifica dalla rete
>>> ip addr add 192.168.1.10/24 dev eth0 / ip addr del 192.168.1.10/24 dev eth0
- Si può visualizzare la configurazione
>>> ip addr show
- Una volta assegnato l'IP bisogna abilitare / disattivare l'interfaccia
>>> ip link set eth0 up / ip link set eth0 up
- Se abbiamo più reti ( 192.168.1.0 / 192.168.2.0 ) abbiamo bisogno di un Router. Il Router ha più indirizzi IP, uno per ogni rete a cui è connesso.
- Puoi visualizzare le informazioni nella routing table
>>> ip route show
- Puoi aggiungere una rotta statica o manuale, il traffico deve passare tramite un default gateway.
>>> ip route add 192.168.1.0/24 via 192.168.2.1
- L'indirizzo 192.168.2.1 è l'IP nel router nella rete destinazione, puoi fare lo stesso per la rotta al contrario
>>> ip route add 192.168.2.0/24 via 192.168.1.1
- Puoi cancellare la rotta inserita in precedenza
>>> ip route del 192.168.2.0/24
- Per accedere ad internet serve una nuova rotta. Si usa di solito la rotta di default, oppure 0.0.0.0/0.
- Quando c'è la rotta di default ogni volta che viene generato un pacchetto non riferito alla rete locale viene inviato al router.
>>> ip route add default via 192.168.50.100
- L'IP 192.168.50.100 è quello del router, su AWS è configurato automaticamente
- In caso si debba attivare la comunicazione dal NodoA al NodoC passando per il NodoB è possibile ripetere i comandi <ip route add> di prima ed inoltre è necessario il forward.
- Di default linux non fa il forward di un pacchetto da una interfaccia di rete ad un altra.
- Per abilitare il forward bisogna settare ad 1 il valore nel file /proc/sys/net/ipv4/ip_forward
- Lo stesso valore deve essere modificato in /etc/sysctl.conf
- Questi comandi sono validi fino al riavvio, se vuoi rendere il tutto persistente devi speficicare la configurazione in /etc/network/interfaces file.
Networking - DNS:
- Ci sono due file importanti per la configurazione del DNS
>>> /etc/resolv.conf
>>> /etc/hosts
- Il file hosts locale ha priorità sul DNS.
- Il DNS è usato in luogo del file host poichè al crescere del numero di nodi nel cluster la gestione dei nomi diventa troppo oneroso
- Di seguito un esempio di records DNS:
192.168.1.10 db.example.com
192.168.1.11 web.example.com
192.168.1.12 app.example.com
- Per evitare di dover scrivere ogni volta l’intero indirizzo possiamo configurare una entry search nel file resolv.conf. Il sistema aggiungerà automaticamente la parte mancante.
>>> cat /etc/resolv.conf
nameserver <ip-del-dns> # punta al file di sopra
search example.com
- Puoi continuare ad usare lo stesso l’indirizzo esteso. Quindi puoi risolvere "db" senza scrivere "db.example.com"
- Per testare la risoluzione di un DNS puoi usare nslookup oppure dig
- La soluzione DNS più utilizzata in k8s è CoreDNS
Networking - Namespace:
- i Namespace sono usati dai conteiner engine (es docker) per implementare l’isolamento a livello di rete.
- L’isolamento fa in modo che i container non abbiano visibilità della configurazione di rete del host.
- il container nel namespace ha la sua tabella di routing e arp così come una sua interfaccia di rete virtuale.
- Per creare un nuovo namespace usa il comando:
>>> ip netns add gialloenv
- Per vedere le network all’interno del namespace devo specificare il nome del namespace, stessa logica del kubectl
>>> ip -n gialloenv link
>>> ip -n gialloenv route add 0.0.0.0/0 via 10.0.128.1
>>> ip -n gialloenv route show
- Se abbiamo più namespace diventa oneroso metterli in comunicazione tra loro. Mettere in comunicazione i vari Namespace è come fare vpc-peering. Se il numero di Namespace è alto bisogna creare delle peer connection per ogni possibile coppia di Namespace. Possiamo risolvere crearendo uno switch virtuale, come se fosse il TGW.
- In questo modo non la rete interna continua ad essere isolata, possiamo risolvere aggingendo un NAT virtuale (SourceNAT).
>>> iptables -t nat -A POSTROUTING -s 192.168.15.0/24 -j MASQUERADE
- Per esporre il container su internet abbiamo anche bisogno di un DestinationNat virtuale (l'equivalente IGW in AWS)
>>> iptables -t nat -A PREROUTING --dport 80 --to-destination 192.168.15.2:80 -j DNAT
Networking - Docker:
- In fase di avvio un container può essere eseguito in diverse opzioni di rete:
-- None: il container non è assegnato a nessuna rete. Il container non è raggiungibile, nè può raggiungere, internet.
-- Hosts: il container condivide la stessa rete del host. Non c’è nessun isolamento a livello di rete. In questa configurazione se esegui un container sulla porta 80 del container allora sara raggiungibile sulla porta 80 del host. Non serve fare nessun port mapping. Se provi ad avviare una nuova istanza dello stesso container però questa non potrà essere eseguita poichè la porta 80 è già occupata.
-- Bridge: In questo caso ogni container ha il suo indirizzo IP. Non condivide l'IP del host come nel caso precedente.
>>> ubuntu@ip-10-0-0-100:~$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
76db995ec23c bridge bridge local
d4883446d072 host host local
b213c7b9c434 none null local
- Puoi vedere la rete BRIDGE (creata di default da docker) usando il comando docker network ls
- L’interfaccia di rete assegnata alle rete bridge è visibile usando il comando ip link
>>> ubuntu@ip-10-0-0-100:~$ ip link
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ad:4f:03:60 brd ff:ff:ff:ff:ff:ff
- I container sono eseguiti nella rete 172.17.0.1/16
>>> ubuntu@ip-10-0-0-100:~$ ip addr
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ad:4f:03:60 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:adff:fe4f:360/64 scope link
valid_lft forever preferred_lft forever
- Quando viene eseguito un container docker crea un namespace appositamente per il container. TODO Verificare, non mi pare lo faccia!
- Per vedere quale indirizzo IP ha il container nella Bridge Network
>>> docker inspect <container-id>
- Quando lanciamo il comando <docker run -d -p 8080:80 nginx> viene automaticamente creato un NAT che espone il container sulla rete del host alla porta 80.
- Si può visualizzare l’impostazione creata automaticamente da docker usando il comando iptables
>>> root@ip-10-0-0-100:/home/ubuntu# iptables -nvL -t nat | grep 8080
0 0 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.6:80
Networking - CNI:
- la configurazione della rete è molto simile tra le varie soluzioni: docker, namespace, stc. Non ha senso ripeterla più volte.
- in k8s viene definita la Container Network Interface che ha lo scopo di gestire le differenze tra le diverse soluzioni senza dover implementare più volte le parti comuni.
- a seconda della versione di k8s docker non è supportato da CNI, k8s crea prima il container nella None Network e poi esegue i comandi di configurazione a "mano"
- Ogni componente in k8s deve comunicare con le altre in un contesto distribuito
- Ogni componente richiede venga aperta una specifica porta:
- kube-api 6443
- kubelet 10250 (la stessa su tutti i worker node)
- kube-scheduler 10251
- kube-controller-manager 10252
- etcd 2379 è la porta a cui tutte le componenti si connettono, 2380 è quella peer-to-peer
- Al momento k8s non mette a disposizione una soluzione managed per mettere in comunicazione i POD all’interno del cluster.
- Tutti i comandi di configurazione della rete devono eseguiti automaticamente da CNI, dobbiamo però abilitare un plugin
- Per sapere tra tutti i plugin disponibili quale sta usando in questo momento k8s possiamo guardare alla configurazione di kubelet.
>>> systemctl status kubelet.service
- Dal comando precedente puoi determinare il valore di --network-plugin=
- Controlla se sono presenti --cni-bin-dir= e --cni-conf-dir= . Se non presenti allora sono settati al default che trovi nella doc
>>> --cni-bin-dir=/opt/cni/bin #default
>>> --cni-conf-dir=/etc/cni/net.d # default
- Documentazione per kubelet https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
- Se ci sono più file in questo path viene scelto il primo in ordine alfabetico: puoi usare il nome per avere più versioni e scegliere quella da usare.
- Come dicevamo prima, al momento k8s non mette a disposizione una soluzione di rete managed. Una delle soluzioni è usate è weaverworks, ma c'è anche calico.
- Al momento c'è ancora un posto nella documentazione dove puoi trovare il comando esatto per deployare il weave network addon:
>>> https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/#steps-for-the-first-control-plane-node (step 2)
- CERCA high availability nella DOC
- Per selezionare un IP “disponibile” abbiamo due opzioni: dhcp, host-local
- Questa informazione viene specificata nel file di configurazione alla sezione ipam.
- weaveworks usa una rete 10.32.0.0/12 che viene equamente splittata su tutti i nodi del cluster.
- Per vedere default gateway è stato assegnato ad un cluster usa: ip route show
node03 $ ip route
default via 172.17.0.1 dev ens3
10.32.0.0/12 dev weave proto kernel scope link src 10.32.0.1 <-- IP usato per uscire su internet
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.48
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
ATTENZIONE
ESISTE UNA POLICY PER NEGARE TUTTO!
https://kubernetes.io/docs/concepts/services-networking/network-policies/
Default allow all ingress traffic
ATTENZIONE
Ingress:
- per usare gli ingress serve un ingress controller. Si può usare nginx, haproxy.. etc
- by default non c’è un Ingress Controller deployato in k8s, devi installarne uno tu.
- Si può deployare un IngressController come si farebbe con un qualsiasi altro Componente K8s. Esso configura automaticamente ogni parte coinvolta nella definizione di un Ingress.
- La configurazione in merito a: err-log-path, keep-alive, ssl-protocols, viene passata alla definizione del ingress controller come ConfigMap.
- Una buona pratica è passare la config map ugualmente, anche se vuota, in modo da poter modificare la configurazione in una fase successiva.
- La config map va specificata tra gli args
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
env:
- name: POD_NAME
valueFrom:
fieldRef:
filedPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
- le variabili di ambiente specificate vengono lette direttamente dai metadata, inoltre serve specificare le porte.
- bisogna esporre il POD al mondo esterno, creiamo un servizio: NodePort
- L'ingress controller monitora il cluster è modifica le componenti di k8s, ad esempio aggiuge la configurazione al DNS, per fare questo ha bisogno dei permessi.
- Viene creato un ServiceAccount (equivalente Ruolo su AWS) a cui tramite RoleBindings viene associato un ClusterRole (equivalente Policy su AWS)
- In definitiva abbiamo bisogno di: Deployment, Service, ConfigMap e Auth=(ServiceAccount)
- kubectl create namespace ingress-space
- kubectl create configmap nginx-configuration -n ingress-space
- kubectl create serviceaccount ingress-serviceaccount -n ingress-space
- kubectl create role.. -n ingress-space
- kubectl create rolebindings.. -n ingress-space
- Una volta configurato il controller dobbiamo aggiungere le regole. Le regole possono essere di diverso tipo:
- si può indirizzare verso un singolo pod
- si può indirizzare un pod in base al path
- si può indirizzare un pod in base al dominio
- Se abbiamo due POD (wear e video), ed abbiamo due servizi ad essi associati, per esporre le componenti su un dominio unico abbiamo bisogno di una Rule e due Path
- L'ingress crea automaticamente un “Default backend”. Se l’utente prova a specificare un path non disponibile in nessuna regola allora questo viene rediretto verso il default.
- Per fare route in base al dominio bisogna specificare anche il campo host. Se non è specificato allora si assume * (tutto il traffico in arrivo).
- Se non viene specificato il path si assume / “root"
- Si possono passare delle configurazioni all'ingress controller, ad esempio questa:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
http://<ingress-service>:<ingress-port>/watch --> http://<watch-service>:<port>/
http://<ingress-service>:<ingress-port>/wear --> http://<wear-service>:<port>/
trasforma il path per ottenere quello / "root"

Kubernetes Security
Kubernetes allows different security mechanisms, like authentication, encrypted communications, network policies, and many more. It is important to know the difference, functionalities, and how you can use them.
Cluster Security
In Kubernetes cluster, kube-apiserver is the main component of the control plane, all actions that take place in the cluster go through this component. kube-scheduler, kube-controller, kube-proxy, kubelet and other components access kube-apiserver as clients. These components are authenticated in the API with TLS certificates and thus establish encrypted connections.
The above image shows the certificates. Kubernetes uses certificates signed by a certificate authority. If you install Kubernetes with kubeadm, the certificates that your cluster requires are automatically generated, most certificates are stored in /etc/kubernetes/pki.
Kubernetes requires PKI certificates for authentication over TLS, both the client and the server must authenticate each other. Il certificato è la parte pubblica, viene condiviso con il cliente ed è usato per cifrare il messaggio destinato al server. Il server usa la key per decifrare il messaggio ricevuto, il server è l'unico ad avere la key giusta. Questa modalità di comunicazione implicitamente autentica il server verso il client.
Tutte le componenti devono parlare con kube-api, quindi devono autenticarsi usando un certificato. L’Administrator, lo scheduler, il controller ed il proxy sono tutti client dal punto di vista del kube-api server. Devono autenticarsi. Il kube-api server a sua volta deve comunicare con l’etc-server e con kubelet, in questo caso kube-api è cliente e deve autenticarsi.
Nella configurazione di kube-apiserver troviamo:
>>> --client-ca-file=/etc/kubernetes/pki/ca.crt è usato dai cliente di kube-api: utenti, scheduler, controller e proxy. Per verificare che i certificati esposti dai client siano validi.
>>> --etcd-cafile: SSL Certificate Authority file used to secure etcd communication. Per verificare che il certificato esposto da ETCD sia valido.
>>> --etcd-certificate=/etc/kubernetes/pki/apiserver-etcd-client.crt SSL certification file used to secure etcd communication. Cifra i messaggi diretti a ETCD.
>>> --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client-key SSL key file used to secure etcd communication. Decifra i messaggi in arrivo da ETCD.
>>> --kubelet-client-certificate: Path to a client cert file for TLS. Il client si autentica, espone il suo certificato che userà kubelet per verificare l'identità di kube-api.
>>> --kubelet-client-key: Path to a client key file for TLS. I messaggi cifrati con kubelet-client-certificate sono decifrati usando kubelet-client-key.
>>> --tls-cert-file: File containing the default x509 Certificate for HTTPS. Viene esposto da kube-api ed usato dai client per comunicare in maniera cifrata.
>>> --tls-private-key-file: File containing the default x509 private key matching --tls-cert-file. Usato da kube-api per decifrare il messaggio cifrato con tls-cert-file.
- Se ci sono problemi con i certificati bisogna controllare i log, ci sono varie modalità:
>>> journalctl -u etcd.service -l, se k8s è configurato come servizio
>>> kubectl logs etcd-master, se k8s è configurato con kubeadm
>>> docker ps -a -> docker logs <container-id-etcd>, se kubeapi non funziona
- Alla certificazione potrebbero esserci dei problemi con i certificati.
- Per aprire un certificato usare il comando < openssl x509 -in /apth/to/cert.crt - text -noout >
Capabilities or Security Context
- Per ragioni di sicurezza puoi anche eseguire un container come non non-root user
>>> docker run --user=1001 ubuntu sleep 3600
- oppure puoi aggiungere capabilities nel seguente modo
>>> docker run --cap-add MAC_ADMIN ubuntu
- Le capabilities sono un modo per suddividere i privilegi normalmente associati ad un superuser in unità distinte.
- Le capabilities possono essere abilitate e disabilitate in maniera indipendente.
- Le capabilities in k8s possono essere specificate a livello di container oppure a livello di POD.
- Se fatta a livello di POD la configurazione è applicata a tutti i container. Se la configurazione è fatta sia a livello di container che a livello di POD in questo caso la configurazione sul container sovrascrive quella sul POD.
- Alla definizione deve essere aggiunta l'opzione securityContext
Network Policies
- tutti i pod possono comunicare tra di loro di default, è possibile limitare la comunicazione usando le network policy.
- posso usare le network policy per impedire che in una three tier architecture il webserver possa comunicare con il database senza passare per l'application server
- Le Network Policy in K8S sono Stateful
- Per applicare una policy di rete ad un POD si usano i selector. La policy di seguito è applicata ad un POD che ha una label ”role: db”
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: db-policy
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
role: api-pod
ports:
- protocol: TCP
port: 3306
- Le Network Policy sono dipendenti dal tipo di soluzione di rete usiamo in K8s. Non tutte le soluzioni di rete supportano le Network Policy. Nel caso in cui la policy non è supportata puoi ugualmente crearla ma non sarà applicata.

Users Permissions and Management
Kubernetes allows different authentication mechanisms for user accounts: Basic HTTP using user and password or tokens, TLS certificates, and protocols like LDAP and Kerberos.
The best practice is to avoid using Basic Authentication and implement TLS certificates instead, although, depending on the size of the organization, it may be more convenient to use LDAP, Kerberos or other systems. These mechanisms can be implemented for users, but there are also service accounts. It is important to know the difference between these two, since Kubernetes handles them differently.
Kubernetes Users Authentication
Users are humans accessing the cluster for administration purposes. In un cluster k8s devi dire chi può accedere al cluster e cosa può fare. Serve autenticarsi verso il Kube ApiServer usando una delle modalità disponibili.
Tutte le rischieste da parte degli utenti arrivano al kube apiserve. Il kube-apiserver autentica la richiesta e poi la porcessa. Kube-ApiServer supporta una modalità basic-auth. Puoi specificare un csv con i dati di login e definire il suo path con l'ozione --basic-auth-file=credentials.csv
Di seguito la procedura per aggiungere un Utente a Kubernetes:
1. Generare una coppia pubblica/privata di chiavi:
$ openssl genrsa -out admin.key 2048
2. Generate the CSR specifying a CN that allows to identify the user:
$ openssl req -new key admin.key -subj "CN=admin /O=system:masters" -out admin.csr
3. Sign the CSR using the Kubernetes cluster's CA or a service account’s key pair:
$ openssl x509 -req -in admin.csr -CA ca.crt -CAkey ca.key -out admin.crt
If it’s an administrator user, add "system:masters" to the Organization field, it indicates administration privileges in the cluster (organizations defined in the subject are used as groups). Per firmare i certificati servono le chiavi dalla CA, questi file devono essere salvati in maniera sicura in un server CA. La certificate-api consente di inviare direttamente a kubernetes la richiesta di firma. Tipicamente l'admin ha accesso ai certificati della CA e può procedere alla firma del suo certificato di autenticazione.
Per aggiungere un utente non admin la procedura è abbastanza simile, tuttavia l’administrator deve validare tutti gli step e approvare la richiesta di firma.
1. Generare una coppia pubblica/privata di chiavi:
$ openssl genrsa -out jane.key 2048
2. Generate the CSR specifying a CN that allows to identify the user:
$ openssl req -new key jane.key -subj "CN=jane" -out jane.csr
Convenzione sui certificati:
- Common names (/CN) are mapped to the name of users
- Organizations (/O) are mapped to the name of groups -subj "/CN=andy/O=network-admin"
Per aggiungere il nuovo utente Jane puoi procedere alla creazione di una CertificateSigningRequest.
$ cat <<EOF | kubectl apply -f -
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: jane
spec:
groups:
- system:authenticated
request: $(cat jane.csr | base64 | tr -d "\n")
signerName: kubernetes.io/kube-apiserver-client
usages:
- client auth
EOF
L’administrator deve approvare la richiesta di firma.
1. kubectl get csr
2. kubectl certificate approve jane
3. kubectl get csr jane -o jsonpath='{.status.certificate}'| base64 -D > csr-jane.crt
Once the certificates have been generated, there are two ways in which the user can authenticate against the Kubernetes API. One is passing the certificate through parameters in each request, as follows:
$ curl https://<kube-apiserver>:<port>/api \
--cacert ca.crt \
--cert admin.crt \
--key admin.key
A more practical way is using a KubeConfig file like the following one:
apiVersion: v1
kind: Config
clusters:
- name: k8s-cluster
cluster:
certificate-authority: ca.crt
server: https://<kube-apiserver>:<port>
contexts:
- name: admin-k8s-cluster
context:
cluster: k8s-cluster
user: admin
users:
- name: admin
user:
client-certificate: admin.crt
client-key: admin.key
Place that file in the user’s $HOME/.kube/config so as not to need to specify the path to this configuration in each kubectl command. Note that in this configuration file it is possible to specify multiple clusters as well as multiple users (with their respective certificates) to access each one of them.
The context defines what user access what cluster, in the previous file it is indicated that the user admin is used to access the cluster k8s-cluster. In case there are multiple contexts defined, the command kubectl config use-context <context-name> can be used to specify the current context.
Normalmente le informazioni di autenticazione andrebbero specificate in tutti i comandi, tuttavia questo è molto scomodo.
- di default il comando kubectl cerca il file config nella cartella $HOME\.kube\config. Così facendo è possibile evitare di specificare il file di configurazione ogni volta.
- di default il comando kubectl cerca il file config nella cartella $HOME\.kube\config. Così facendo è possibile evitare di specificare il file di configurazione ogni volta.
- Il KubeConfig file usa un formato ben preciso, in esso possiamo identificare tre diverse sezioni:
- Clusters: definisce a cosa ci stiamo collegando
- User: definisce chi siamo
- Contexts: definisce quale user deve essere usato per loggare in un certo cluster
- Questa operazione non crea utenti o cluster, permette di riferirsi ad entità già esistenti.
>>> kubectl config -h
- Nel context puoi specificare il namespace di default
contexts:
- name: cname
context:
cluster: cluster-name
user: user-name
namespace: dev
- Controlla la Doc: https://kubernetes.io/docs/reference/access-authn-authz/certificate-signing-requests/
- Usa la Docs di k8s: https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/
Kubernetes Service Accounts
Service accounts are for processes, services or applications that need to access the cluster.
The case of service accounts is different since Kubernetes can manage them natively. The following command creates a service account in the current namespace and an associated secret:
$ kubectl create serviceaccount jenkins
The associated secret name can be obtained by running:
$ kubectl get serviceaccounts jenkins -o yaml
The created secret holds the public CA of the API server and a signed JSON Web Token (JWT).
$ kubectl get secret jenkins-token-wcl6d -o yaml
The signed JWT can be used as a bearer token to authenticate as the given service account. Normally service accounts are used into pods (by specifying the serviceAccountName field in the pod spec) for in-cluster access to the API server but they can be used from outside the cluster as well.
Important to note: because service account tokens are stored in secrets, any user with read access to those secrets can authenticate as the service account. Be cautious when granting permissions to service accounts and read capabilities for secrets.
Kubernetes Authorization
- Voglio avere la possibilità di configurare i permessi affinchè ogni utente possa fare soltanto il minimo necessario.
- Voglio inoltre poter introdurre delle restrizioni a livello di namespace.
- Ci sono diverse tipologie di autorizzazioni:
- ABAC: autorizzazione a livello di Attribute Based Access Control. Nel modello ABAC viene creato un policy file che contiene tutti i permessi da assegnare all’utente, successivamente il file viene inviato al api-server. Ogni volta che biosgna aggiungere o modificare una policy bisogna intervenire sul file di policy e riavviare manualmente il kube-api server. Gestire la modalità ABAC è quindi molto complesso.
- RBAC: Role Based Access Control. La modalità RBAC rende il tutto più facile. Invece di associlare i permessi direttamente agli utenti creiamo dei ruoli (le policy in aws). In questo modo è sufficiente modificare il ruolo.
- Webhook, danno la possibilità di esternalizzare la gestione dei permessi.
>>>> openssl x509 -noout -text -in csr-giallo.crt
>>> kubectl create clusterrole network-admin \
--verb=create --verb=get --verb=list --verb=update --verb=delete --resource=ingressclasses,ingresses,networkpolicies --dry-run=client -o yaml
>>> kubectl create clusterrolebinding network-admin-binding-giallo --clusterrole=network-admin --user=giallo --dry-run=client -o yaml
>>> kubectl config set-credentials giallo --client-key=giallo.key --client-certificate=csr-giallo.crt --embed-certs=true
>>> kubectl config get-clusters
>>> kubectl config get-users
>>> kubectl config set-context giallo --cluster=kind-kind --user=giallo
>>> kubectl config use-context giallo
- Puoi verificare di avere i permessi per fare una certa operazione. Se sei un administrator puoi anche impersonare altri utenti e verificare i permessi.
- Puoi anche limitare l’accesso a livello di singola risorsa, supponiamo tu voglia limitare l’accesso al singolo pod usando:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: custom-ns
name: dev
rules:
- apiGroups: [""]
resources: ["pods"]
resourceNames: ["my-pod"]
verbs: ["update", "get", "create"]
- Per limitare l’accesso al singolo namespace, puoi specificarlo nel metadata: custom-ns.
- Quando parliamo di Role & RoleBindings questi sono legati ad uno specifico Namespace. Se non diversamente specificato questi sono creati nel Namespace di default.
- Esistono tuttavia alcune risorse che esistono fuori dal concetto di Namespace. Per ottenere la lista completa delle risorse:
>>> kubectl api-resources --namespaced=true
>>> kubectl api-resources --namespaced=false
- ClusterRole sono Role che si riferiscono alle risorse di cluster. In realtà puoi anche creare un ClusterRole per una risorsa all’interno del namespace. Questo tipo di configurazione consente all’utente di accedere alla risorse in tutti i namespaces. Questa configurazione è utile, ad esempio, per consentire l’accesso all’utente a tutti i secrets in tutti i namespaces.
Node Authorization
- Node: autorizzazione a livello di nodo. La Node Authorization si riferisce alle autorizzazioni necessarie a mettere in comunicazione le varie componenti di k8s, l’autenticazione avviene tramite certificati. Ogni richiesta che arriva dal gruppo “system-node” viene autorizzata dal Node Authorizer. Quali permessi garantire dipende dalla componente individuata dal certificato (????????)
- Nel comando di avvio di kube-apiserver puoi specificare --authorization-mode=Node,RBAC per abilitare in ordine la modalità Node e poi RBAC, se non fa match la prima allora c'è la seconda. Puoi anche attivare ABAC, Webhook insieme a AlwaysAllow (consenti sempre) e AlwaysDeny (nega sempre). Se non diversamente specificato AlwaysAllow è la modalità di default.
- Quando un utente effettua una richiesta il primo a rispondere è il Node. Siccome il Node gestisce solo le rischieste a livello di nodo risponderà con Deny. La richiesta a questo punto viene inviata al successivo nella catena: RBAC. E così via..

Design and Install K8s Cluster & kubeadm
CKA..
How to Install Kubernetes?
>>> sudo apt-get install -y kubelet kubeadm kubectl
- https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
>>> kubeadm init
- https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
- Eseguire alcuni comandi che suggerisce lui alla fine
- Salvare il token di join
- ssh nel nodo e fare join sul master
>>> kubeadm join ..
- Installare il plugin di rete
- https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
>>> kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
- Installare ingress controller
- https://kubernetes.github.io/ingress-nginx/deploy/

Cluster Maintenance
OS Upgrade, Cluster Upgrade, Backup and Restore ETCDCTL
Master HA:
- per cluster molto grandi può convenire separare alcune componenti
- se fallisce il master i worker (e tutte le risorse) continuano a funzionare, ma senza master in caso di problemi nessuno può ripristinare il servizio
- kube-apiserver può lavorare in modalità active-active con un bilanciatore
- il control manager non può lavorare in modalità multi-master, deve esere eletto un leader. Ogni controller-manager prova ad acquisire il lock su un service, il primo che riesce viene eletto. La procedura viene ripetuta periodicamente per gestire eventuali fallimenti.
>>> kube-controller-manager --leader-elect true [other options] --leader-elect-lease-duration 15s --leader-elect-renew-deadline 10s --leader-elect-retry-period 2s
- lo stesso si verifica con lo Scheduler. Non può lavorare in modalità Active-Active perchè si andrebbero a generare azioni duplicate.
- Per quanto riguarda ETCD abbiamo due opzioni:
>>> Stacked Topology: più facile da gestire e configurare, meno server, più rischiosa in caso di fallimento. Il processo ETCD è installato insieme agli altri nel cluster.
>>> External ETCD Topology: Meno rischiosa, un fallimento su una degli altri componenti non impatta ETC. Servono più server ed è più difficile da configurare.
- In entrambe le modalità dobbiamo assicurarci che il API Server punti al endpoint corretto per ETCD.
>>> --etcd-servers= lista di indirizzi a cui risponde ETCD
- ETCD è un database key-value nosql distribuito. In riferimento al CAP Theorm è implementato come CP. Ci sta un solo master. In fase di scrittura tutte le richieste arrivano al master, in fase di lettura tutti i nodi possono rispondere.
- ETCD usa un meccanismo di elezione chiamato RAFT. Ogni nodo inizializza un timer random, allo scadere fa una richiesta a tutti gli altri di essere leader. I nodi che ricevono la richiesta accettano. Il nuovo leader trasmette un segnale a tutti gli altri ad indicare che è healthy, diversamente il processo di elezione viene ripetuto. Serve il Quorum (numero dispari di nodi).
>>> l'impostazione --initial-cluster in etcd.service ci consente di definire dove gli altri nodi del cluster si trovano.
Cluster Maintenance
- drain: il comando <kubectl drain node01> termina in maniera sicura i POD che vengono poi spostati su altri nodi. In questo modo è possibile fare manutenzione sul nodo. Il Nodo viene Taint NoSchedule in questo modo nessun nuovo POD può essere eseguito finchè non è esplicitamente rimossa la restrizione.
- uncordon: il comando <kubectl uncordon node01> può essere eseguito una volta completata la manutenzione. Rimuove la limitazione allo scheduler, ma non rimette automaticamente al loro posto i vecchi POD spostati in fase di drain.
- cordon: il comando <kubectl cordon node01> marca il nodo come NoSchedule senza fare il drain.
- tutte le componenti devono essere della stessa versione del kube-apiserver, oppure al massimo le altre componenti possono essere fino a 2 versioni precedenti.
- ricorda: kube-apiserver è la componente con cui interagiamo e che interagisce con tutte le altre.
- questa differenza tra le versioni mi consente di effettuare degli upgrade live. Possiamo aggiornare una componente per volta.
- supportate sempre le ultime tre minor version. Quindi se v1.12 è l’ultima release k8s supporta anche v.1.11 e v1.10: va considerata la minor version secondo la convezione "version.minor.release"
- per aggiornare il cluster posso: 1. delegare al cloud provider, 2. usare kubeadm, 3. manualmente una componente per volta
- bisogna aggiornare prima il master e poi tutti gli altri
- kubeadm non installa/aggiorna kubelet
Aggiornamento del Master
- durante la manutenzione del master le componenti kube-apiserver, kube-scheduler e controller-manager vanno down.
- questo non significa che glie le applicazioni sui Workers vanno down.
- non puoi accedere alle api, non puoi deployare applicazioni o cancellare pod, il controller-manager non andrà a sostituire i POD in caso di fallimento.
1. aggiornare kubeadm, questo tool segue le stesse logiche di versionamento di kubernetes. Usare il comando <apt-get upgrade -y kubeadm=1.12.0-00>
2. verificare la possibilità di aggiornare facendo un plan. Usa il comando <kubeadm upgrade plan>. ATTENZIONE: Possiamo aggiornare una versione per volta.
3. applicare l'avanzamento di una versione usando il comando <kubeadm upgrade apply v1.12.0>
- Dopo l’aggiornamento se esegui il comando get nodes fa ancora vedere la versione precedente, il comando mostra la versione del kubelet per ogni nodo non la versione del api-server.
4. aggiornare kubelet sul master node (se presente) usando il comando <apt-get upgrade -y kubelet=1.12.0-00>
5. riavviare kubelet <systemctl restart kubelet>
- A questo punto il comando <kubectl get nodes> mostra correttamente l'aggiornamento del master.
Aggiornamento dei Nodi
- aggiornare tutti insieme, in questo caso abbiamo disservizio.
- aggiornare un nodo alla volta, facciamo il drain dei nodi e li aggiorniamo fino ad aggiornare tutto
- aggiungere nuovi nodi al cluster, i nuovi avranno la versione aggiornata, si possono cancellare uno per volta quelli vecchi usando il drain.
1. Fare Drain del Nodo, usa il comando <kubectl drain node01>, poi fai ssh nel nodo
2. Aggiornare kubeadm, usa il comando <apt-get upgrade -y kubeadm=1.12.0-00>
3. Aggiornare kubelet, usa il comando <apt-get upgrade -y kubelet=1.12.0-00>
4. Aggiornare la configurazione del nodo <kubeadm upgrade node config --kubelet-version v1.12.0.00>
5. Riavviare kubelet <systemctl restart kubelet>
- La medesima procedura deve essere ripetuta su tutti gli altri nodi
- Dopo queste operazioni il nodo tornerà UP con la nuova versione, è necessario ri-abilitare la schedulazione su questo nodo usando il comando kubectl uncordon node01
Backup del Cluster
- è possibile esportare tutto quello che è nel cluster in un file yaml
>>> kubectl get all --all-namespaces -o yaml > all-deploy-services.yaml
- puoi fare il backup di ETCD, invece di salvare le risorse (come fatto prima) un altro modo è fare il backup di ETCD.
- Puoi usare una utiliti di sistema < ETCDCTL_API=3 etcdctl ..> per fare lo snapshot.
>>> etcdctl snapshot save -h
>>> etcdctl snapshot restore -h
1. Far riferimento alla doc https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/.
>>> ETCDCTL_API=3 etcdctl \
snapshot save <backup-file-location> \
--endpoints=https://127.0.0.1:2379 \ # oppure --advertise-client-urls
--cacert=<trusted-ca-file> \
--cert=<cert-file> \
--key=<key-file>
2. Esplora la condifurazione del ETCD-POD, nella definizione del command ci sono i parametri richiesti dal comando precedente.
3. Verifica lo snapshot ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
4. Per riprisitnare il db partendo da uno snapshot è necessario fermare il servizio kube-apiserver e ripristinare il backup. Se k8s è isntallato con kubeadm puoi temporaneamente cancellare il POD statico in /etc/kubernetes/manifest
5. Per ripristinare il backup partire dal comando usato per crearlo ad aggiungere i parametri obbligatori, puoi recuperarli dalla definizione di etcd.
>>> ETCDCTL_API=3 etcdctl \
snapshot restore <backup-file-location> \
--endpoints=https://127.0.0.1:2379 \ # oppure --listen-client-urls
--cacert=<trusted-ca-file> \
--cert=<cert-file> \
--key=<key-file> \ # Fino a qui identico al precedente
--data-dir=/var/lib/etcd-from-backup \
--initial-advertise-peer-urls=https://10.0.0.100:2380 \
--initial-cluster=ip-10-0-0-100.us-west-2.compute.internal=https://10.0.0.100:2380 \
--initial-cluster-token="etcd-cluster-1" \
--name=ip-10-0-0-100.us-west-2.compute.internal \
--skip-hash-check=true # Alcune volte da errore. Error: expected sha256 [...], got [...]
6. I parametri obbligari sono recuperabili facendo help sul comando etcdctl, come completarli è presente mapping 1:1 nella configurazione di etcd.
7. Modificare il POD statico ETCD aggiungendo:
>>> --initial-cluster-token="etcd-cluster-1"
>>> replace --data-dir=/var/lib/etcd con --data-dir=/var/lib/etcd-from-backup in ogni punto
8. Fai ripartire kube-apiserver
- l'opzione --data-dir va settato ad un percorso nuovo, ad una cartella che non esiste. Viene creata Automaticamente.
- dal master è possobile raggiungere ETCD usando --listen-client-urls

Troubleshooting
CKA..
Troubleshooting Tips
- Doc k8s: https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application/
- prima a fare una curl sul servizio
- verifica i selettori
- controlla lo stato dei pod
- consulta i log kubectl logs my-pod --previous # dump pod logs (stdout) for a previous instantiation of a container
- systemctl | grep running = per la lista di tutti i servizi running
- controlla lo stato dei nodi nel cluster
- Lo status può essere True | False nei casi in cui il disco ad esempio è pieno, quando lo stato è Unknown significa che c’è una perdita di comunicazione con il master, puoi controllare la colonna LastHeartbeatTime per controllare l’ultimo controllo.
- Controlla lo stato del servizio Kubelet.
- Controlla lo stato dei certificati. openssl x509 /path/to/certificate.crt -text
- service | grep running = per la lista di tutti i servizi running
- journalctl -u kube-apiserver
- NON PUOI CREARE UN INGRESS CROSS NAMESPACE, bisogna che ne crei uno nuovo nello stesso namespace
- VIM premere : e poi scrivere set number per visualizzare i numeri
- ATTENZIONE: kubectl api-resources -o wide
- Il comando kubectl api-resources è molto importante, è utile per recuperare l’informazione sul apiGroups e sui verbs.
- You have been notified that the Kubernetes cluster that you administer has been behaving strangely. A team member has told you they suspect one of the cluster's master components is at fault. How can you quickly check on the status of the master components?
>>> kubectl get componentstatuses
- Visualizzare lo stato del nodo in caso di fallimento. Ci sono dei Flag, controllare se sono a False oppure True per indivuduare la causa, se sono Unknown allora non c'è comunicazione tra il nodo ed il master. Controllare il nodo facendo ssh in esso.
>>> kubectl describe node
- Visualizzare i log dei POD, usare previous per vedere i log del container fallito in precedenza
>>> kubectl logs -container-id- -f -previous

Others
Altro:
- CoreDNS
What is the IP of the CoreDNS server that should be configured on PODs to resolve services?
Run the command kubectl get service -n kube-system and look for cluster IP value.
- Il drain di un nodo non può fare eviction di un POD che non è parte di un ReplicaSet/Deploy etc..
- I POD creati singolarmente vengono persi dopo il drain
- Ci sono diversi modi per entrare in un container:
>>> docker exec -it 3d53596c5f8f sh per entrare in un container e vedere i logs
>>> kubectl exec webapp -- cat /log/app.log
>>> docker exec -it <container-id> /bin/bash
- At this moment in time, there is still one place within the documentation where you can find the exact command to deploy weave network addon:
>>> https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/#steps-for-the-first-control-plane-node (step 2)
- Cercare high availability nella documentazione
- K8s mette a disposizione diverse interfacce. Le interfacce rendono K8s estendibile.
CRI = Container Runtime Interface
CNI = Container Network Interface
CSI = Container Storage Interface
- Chi vuole “essere parte” del ecosistema di K8s deve semplicemente implementare queste interfacce.
https://kubernetes.io/docs/setup/best-practices/certificates/
- il Controller Manager gestisce i meccanismi di creazione dei certificati
>>> - --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
>>> - --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
Ho to Pull an image from Private Registry
- your.private.registry.example.com/janedoe/jdoe-private:v1
>>> your.private.registry.example.com: dominio
>>> janedoe: user-name
>>> jdoe-private:v1: img
- Puoi anche omettere lo user-name se coincide con il nome dell'immagine
- Le credenziali per fare il login sono lette da un Secret
Pull Image Private Repository:
- Puoi cercare "pull private image" sulla documentazione ed ottenere: https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
- Oppure puoi creare il secret a mano
kubectl create secret docker-registry dockercred \
--docker-server=private-registry.io \
--docker-username=registry-user \
--docker-password=registry-password \
--docker-email=registry-user@org.com
- Nel POD va specificata l'opzione imagePullSecrets
Related posts

Certified Kubernetes (Part 1)
This blog post will provide an introduction to Kubernetes, what it is, and how you can use it, and build…
Comments